This is the chart of hits to Findory's webservers (excluding robots and redirects):
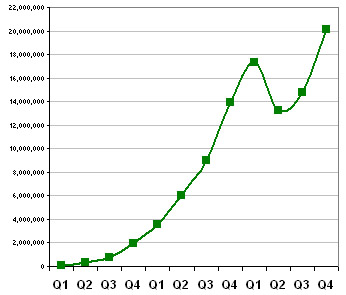
It shows a big jump in Q4 2006. Good news, it would seem. But, after digging in, much of this growth appeared to be on Findory's feeds, traffic that may not be easily monetizable.
I did a second analysis that attempted to limit the data to more directly monetizable page views. The data on this was only easily available for the most recent seven quarters.

This trend looks similar, but shows a bigger decline after Q1 2006 and smaller growth in Q4 2006. The growth is good, but it is unfortunate that so much of it is on the feeds and other areas that are not as valuable to Findory.
Robot and similar traffic is excluded from the data going into these analyses but, I have to say, it is amazing how much robot traffic Findory gets. Web crawlers hammer the poor webservers, generating another x2-3 the traffic numbers reported here in total. I would be curious to know if other news sites with lots of rapidly changing content also see this level of crawler interest.
For more on the Q1 2006 drop, see the posts on Findory's traffic after Q2 2006 and Q3 2006.

4 comments:
Findory offers a convenient API, which, unlike google, doesn't limit the number of searches. I'm not sure how they plan to make money out of this.
On www.wine-searcher.com (a similarly fast changing site), we are also staggered by the amount of robot traffic we receive. Not quite your multiples however, 50/50 real users versus spider traffic.
"I would be curious to know if other news sites with lots of rapidly changing content also see this level of crawler interest."
My news aggregator (frisim.com) has, for every 100 pages by a browser, 140 pages from robots. This covers robots and pages as defined in a default AWStats installation. That is, a factor 1.4 between "not viewed traffic"/"viewed traffic" in AWStats. Cheers /Clas
(sorry if I comment multiple times - I'm in China, blogger.com is all in Chinese, and I can't read Chinese)
Oh yes, over at Simpy, the crawler/feed aggregator situation is the same.
Here are some charts from 7-8 months ago.
Guess who eats my bandwidth?
Guess who hogs the CPU?
Guess who keeps the disk head moving the most?
Post a Comment