When I was at Amazon, I was a strong believer in the idea of launching early and often. In our group, new features typically launched in weeks, then were modified repeatedly. Often, projects were completed in just days. Projects spanning multiple months were unusual.
I carried this philosophy over to Findory. Findory was built on rapid prototyping and early launches.
When Findory first started, the company was targeting personalized web search.
A quick prototype revealed the need for more data about user behavior. The recommendation engine reached out to ask, "What have other users done?" and always got the answer, "I don't know."
For a brief time, I looked at whether I could acquire the necessary information about user behavior. Were there old weblogs available from major search engines (without restrictions for commercial use)? Would Yahoo consider a deal to share an anonymized sample of their logs? Could I acquire logs from an ISP (as Snap.com later did)? No, no, no.
With some amount of frustration, I abandoned this web search prototype and switched to news. With news, bootstrapping is a bigger issue. Old news is no news, as they say. The advantage some may have from massive amounts of log data is diminished by the need to a good job handling the cold start problem.
I spent some time prototyping a personalized news application. I iterated. Eventually, it looked good in my tests.
I decided to launch Findory.com as a personalized news website in Jan 2004. At that point, Findory did not have its own crawl. Findory did not even have a search engine. But the personalization worked. I iterated on it rapidly over the next few months, launching new versions nearly daily, including a Findory crawl and a custom news search engine.
In June of 2004, I launched a version of Findory for weblogs. The underlying personalization engine had to be adapted for blog articles, articles that are often short, almost always opinion, and frequently crappy. Several iterations on an internal prototype tuned a version of the engine to the characteristics of weblogs. A crawl had to be created to cover the most interesting and useful weblogs. Tools were needed to process new weblogs and filter out spam weblogs (splogs).
With Findory and weblogs, I made the mistake of launching as a separate site called Blogory. It was a foolish decision and one that later would need to be reversed. Blogory is now merged into Findory.
Over the next many months, we iterated, iterated, and iterated. There were several redesigns of the website, all looking to figure out what format worked best for readers.
In May of 2005, personalized advertising launched. Findory's advertising (which is sourced from Google) is targeted by Findory not only to the content of the page, but also to the specific history of each Findory reader. Findory focuses the ads both based on what each reader is currently doing and on what that person has done in the past.
Now, in 2006, Findory has many products: news, blogs, video, podcasts, advertising, and (alpha) web search. Findory is personalizing information in many different areas.
Looking back, I think a few things are critical for a strategy of launching early and often.
First, you need developer websites, a full testing environment where programmers have a toy version of the website with which they can tinker. To iterate and test, you need to see everything working together in a sandbox environment.
Second, you need some objective test of the ideas, some measure of what is good or bad. You need some way of evaluating the prototypes even if it is not ideal.
One important point is that not all prototypes should be launched. Yes, I know, you worked hard on that thingie. But, many things should be throwaway, just experiments. At Findory, many things did not look good during testing and were abandoned. They were a path not followed. That work is still valuable, mind you. We learned what works and what does not work. That information is valuable even if the feature was discarded.
Finally, I want to point out that the strategy of launch early and often is not without cost. It is true that some people and press looked at early versions of Findory.com and saw things that were still really prototypes. Sometimes, they judged it harshly and never returned. That has real cost. The damage to the brand is not insignificant.
I remain a strong believer in launching early and often for web development. Findory is learning constantly. We get immediate feedback. We get rapid gratification. The benefits far outweigh the costs.
Saturday, July 29, 2006
Friday, July 28, 2006
Microsoft, search, and the desktop
Steve Lohr at the NYT reports on Microsoft's plans for search, integration into the desktop and Office applications:
See also my previous post, "Using the desktop to improve search", where I said, "Is it really natural to go to a web browser to find information? Or should information be readily available from the desktop and sensitive to the context of your current task?"
Internet search, according to Microsoft, will increasingly become seamlessly integrated into the Windows desktop operating system, Office productivity software, cellphones powered by Windows, and Xbox video games.More detail and the full context is available from the transcript of one of the sessions of Microsoft's analyst day. I particularly like this additional snippet: "It's not just about search, it's about being able to find, ... share, and use the information that you have."
"Search will not be a destination, but it will become a utility" that is more and more "woven into the fabric of all kinds of computing experiences," said Kevin Johnson, co-president of Microsoft's platforms and services division.
See also my previous post, "Using the desktop to improve search", where I said, "Is it really natural to go to a web browser to find information? Or should information be readily available from the desktop and sensitive to the context of your current task?"
Tuesday, July 25, 2006
Starting Findory: Legal goo
Startups have to do a fair amount of legal goo. Finding a good lawyer is important not just for legal advice, but also business advice and contacts.
It is hard to find good lawyers. If you can, try to find someone with substantial startup business experience in your sector (e.g. internet startups). Talking with someone who understands your business, is excited about it, and can offer parallels to others is extremely valuable.
Unfortunately, legal work is extremely expensive. $400+/hour is not uncommon. While many law firms will delay billing for small startups and may even write off some of the work, lawyers can do major damage to the burn rate.
Even simple things like assisting with negotiating an NDA can cost a few thousand dollars. That can be annoying. Folks at large companies you might be talking to think of legal work as costless or, at least, cost is unimportant. So, biz dev people at big companies are happy to play games all day long with you with legal agreements.
But, in these discussions, each time your little startup needs to turn to your legal team, you rip through the nest egg. More substantial legal issues may cost enough to even threaten the life of a startup.
On the issue of intellectual property protection, Findory did seek patents, but I am not sure I would recommend this path to others. Filing was expensive ($10k+) and extremely time consuming, stealing time and money away from building products, helping customers, and innovating on the core engine. Even worse, I now fear that patents provide little protection for a small startup. Not only do they take years to issue, but also they cost at least $1M and several years to attempt to enforce; clearly that amount of time and money is impossible for a small startup.
There are a few other pieces of legal goo I will comment on briefly. Watch out for conflicts of interest with bigger clients of the firm; Findory lost its first two law firms suddenly and inconveniently when they bailed due to conflicts of interest. Choose your incorporation carefully; LLC or S Corp provides tax advantages, but you need to be C Corp to take some types of funding, and converting can be a bit of a pain. Put reasonable terms of use and privacy policy pages up on your website. Grab related domain names; I neglected to get a common misspelling for findory.com -- findery.com -- which still causes headaches sometimes. Make sure your intellectual property and ownership agreements are in place for anyone who does work for your firm, including your contractors.
Overall, looking back at my experience, I think a mistake I made in the very early days of Findory was thinking too much of law firm as a mere source of legal advice. In fact, the most valuable interactions with our lawyers were the business advice and connections they provided. Despite the cost, it is worthwhile to find one that can advise you on all aspects of your business.
I want to end by emphasizing that it is important to understand that any business discussions with any large firm are going to be costly for a startup. Not only do you have the risk of disclosing information (regardless of NDAs) to a potential competitor, but also the cost of any legal frameworks necessary for the discussions can be risky for a tiny startup to bear. Be very careful with who you decide to talk to and make sure those discussions are worth the cost.
It is hard to find good lawyers. If you can, try to find someone with substantial startup business experience in your sector (e.g. internet startups). Talking with someone who understands your business, is excited about it, and can offer parallels to others is extremely valuable.
Unfortunately, legal work is extremely expensive. $400+/hour is not uncommon. While many law firms will delay billing for small startups and may even write off some of the work, lawyers can do major damage to the burn rate.
Even simple things like assisting with negotiating an NDA can cost a few thousand dollars. That can be annoying. Folks at large companies you might be talking to think of legal work as costless or, at least, cost is unimportant. So, biz dev people at big companies are happy to play games all day long with you with legal agreements.
But, in these discussions, each time your little startup needs to turn to your legal team, you rip through the nest egg. More substantial legal issues may cost enough to even threaten the life of a startup.
On the issue of intellectual property protection, Findory did seek patents, but I am not sure I would recommend this path to others. Filing was expensive ($10k+) and extremely time consuming, stealing time and money away from building products, helping customers, and innovating on the core engine. Even worse, I now fear that patents provide little protection for a small startup. Not only do they take years to issue, but also they cost at least $1M and several years to attempt to enforce; clearly that amount of time and money is impossible for a small startup.
There are a few other pieces of legal goo I will comment on briefly. Watch out for conflicts of interest with bigger clients of the firm; Findory lost its first two law firms suddenly and inconveniently when they bailed due to conflicts of interest. Choose your incorporation carefully; LLC or S Corp provides tax advantages, but you need to be C Corp to take some types of funding, and converting can be a bit of a pain. Put reasonable terms of use and privacy policy pages up on your website. Grab related domain names; I neglected to get a common misspelling for findory.com -- findery.com -- which still causes headaches sometimes. Make sure your intellectual property and ownership agreements are in place for anyone who does work for your firm, including your contractors.
Overall, looking back at my experience, I think a mistake I made in the very early days of Findory was thinking too much of law firm as a mere source of legal advice. In fact, the most valuable interactions with our lawyers were the business advice and connections they provided. Despite the cost, it is worthwhile to find one that can advise you on all aspects of your business.
I want to end by emphasizing that it is important to understand that any business discussions with any large firm are going to be costly for a startup. Not only do you have the risk of disclosing information (regardless of NDAs) to a potential competitor, but also the cost of any legal frameworks necessary for the discussions can be risky for a tiny startup to bear. Be very careful with who you decide to talk to and make sure those discussions are worth the cost.
Monday, July 24, 2006
Friday, July 21, 2006
Starting Findory: On the cheap
When I started Findory, I was extremely sensitive to burn, probably too sensitive.
Maybe having witnessed all the dot com flameouts caused me to be overly cautious, but I wanted to be very careful about money flowing out the door. Many companies do fail early simply by running out of cash. I thought the best way to avoid this was to be careful about spending money.
Findory was built on the cheap. It is self-funded. There is no office space; the company is virtual. There is almost no marketing or advertising.
There are no salaries or benefits at Findory. For most tech startups, salaries dominate the burn rate. Even at 1/3 salary, each additional employee is about $4-6k/month (fully loaded, includes benefits, expenses, office space, etc.) At full salary, it is about $10-15k/month. Salary and benefits would have burnt through initial funding in less than a year.
By the way, it is worth noting that not drawing a salary is roughly equivalent to taking a salary but investing an equivalent amount immediately back in the startup. The latter is a lot more complicated, but both serve to fund the company using the money normally paid in salaries and benefits.
Findory uses free open source software (Apache, MySql, Linux, Perl, Berkeley DB). This allows the company to keep its costs low in its infancy. A quick note here, using Fedora Linux was a mistake. As it turns out, the upgrade path to get patches on major releases (e.g. Core 3 -> Core 4) is quite painful.
Findory uses cheap, leased, commodity servers. Findory currently runs on six servers. The cost per server is under $100/month. They are simple, low end, AMD boxes with a reasonable amount of memory and a cheap IDE disk.
Rather than pay for a news feed, Findory runs its own crawl. That allows us to customize the crawl to our needs and quickly launch new products (e.g. video, podcasts), but does take a fair amount of time to maintain and extend.
In retrospect, I think I have been too cheap. The tradeoff here is between death by burn versus death by resource starvation. While Findory has lived a long time with very low burn, it has been starved of resources, slowing growth and making it difficult to pursue many paths for expanding the products.
Update: By the way, I always welcome comments, but I especially would love to hear feedback in this particular series. Think I should have done something differently? Please comment and let me know. Think I have analyzed the issues incorrectly? Chime in and tell me about it. I would enjoy hearing what you think.
Update: There are some good discussions going on in the comments to this post.
Maybe having witnessed all the dot com flameouts caused me to be overly cautious, but I wanted to be very careful about money flowing out the door. Many companies do fail early simply by running out of cash. I thought the best way to avoid this was to be careful about spending money.
Findory was built on the cheap. It is self-funded. There is no office space; the company is virtual. There is almost no marketing or advertising.
There are no salaries or benefits at Findory. For most tech startups, salaries dominate the burn rate. Even at 1/3 salary, each additional employee is about $4-6k/month (fully loaded, includes benefits, expenses, office space, etc.) At full salary, it is about $10-15k/month. Salary and benefits would have burnt through initial funding in less than a year.
By the way, it is worth noting that not drawing a salary is roughly equivalent to taking a salary but investing an equivalent amount immediately back in the startup. The latter is a lot more complicated, but both serve to fund the company using the money normally paid in salaries and benefits.
Findory uses free open source software (Apache, MySql, Linux, Perl, Berkeley DB). This allows the company to keep its costs low in its infancy. A quick note here, using Fedora Linux was a mistake. As it turns out, the upgrade path to get patches on major releases (e.g. Core 3 -> Core 4) is quite painful.
Findory uses cheap, leased, commodity servers. Findory currently runs on six servers. The cost per server is under $100/month. They are simple, low end, AMD boxes with a reasonable amount of memory and a cheap IDE disk.
Rather than pay for a news feed, Findory runs its own crawl. That allows us to customize the crawl to our needs and quickly launch new products (e.g. video, podcasts), but does take a fair amount of time to maintain and extend.
In retrospect, I think I have been too cheap. The tradeoff here is between death by burn versus death by resource starvation. While Findory has lived a long time with very low burn, it has been starved of resources, slowing growth and making it difficult to pursue many paths for expanding the products.
Update: By the way, I always welcome comments, but I especially would love to hear feedback in this particular series. Think I should have done something differently? Please comment and let me know. Think I have analyzed the issues incorrectly? Chime in and tell me about it. I would enjoy hearing what you think.
Update: There are some good discussions going on in the comments to this post.
Wednesday, July 19, 2006
Yahoo and MSN cannot compete?
What is the problem at Yahoo and MSN? After four years of trying, they just seem to be slipping further and further behind.
First, MSN showed a drop in web search market share, down to 12.9% from 15.3% a year ago.
Now, as Saul Hansell reports, Yahoo is struggling. Some excerpts:
Update: A couple days later, Saul Hansell reports, "Google Profit Surges on Strong Search Advertising".
Update: And Pamela Parker notes that "revenues at Microsoft's MSN declined 3 percent year-over-year." [via Barry Schwartz]
Update: Tony Schneider (former VP at Yahoo) says, "Yahoo has lost its appetite for experimentation." [via Findory]
First, MSN showed a drop in web search market share, down to 12.9% from 15.3% a year ago.
Now, as Saul Hansell reports, Yahoo is struggling. Some excerpts:
[Yahoo] reported weak revenue from Internet search advertising in the second quarter and a delay in a critical project that is meant to increase search revenue ... [as] it has been struggling to rebuild its search service.Why are these companies unable to compete against Google?
Google ... produces 40 percent more revenue from each search than Yahoo does ... thanks to software that is better at selecting relevant text advertisements to place on a page of search results.
Terry Semel, Yahoo's chief executive, told investors ... that Project Panama, the company's effort to match Google's ad-selection technology, would be delayed by at least three months ... The two-year-old project is already many months behind its original schedule.
[Analyst Safa] Rashtchy said he estimated that Yahoo's revenue from search advertising actually fell in the quarter .... There [also] were some signs that the growth of Yahoo's vast audience had stopped.
Update: A couple days later, Saul Hansell reports, "Google Profit Surges on Strong Search Advertising".
Update: And Pamela Parker notes that "revenues at Microsoft's MSN declined 3 percent year-over-year." [via Barry Schwartz]
Update: Tony Schneider (former VP at Yahoo) says, "Yahoo has lost its appetite for experimentation." [via Findory]
Monday, July 17, 2006
Starting Findory: In the beginning
For the first post, I wanted to talk a bit about how I was motivated to start Findory.
The fundamental idea behind Findory is to apply personalization to information. Help people deal with information overload. Help cut through the noise and filter up the good stuff. Help people find what they need.
Personalization can do this using implicit information about your wants and needs, learning from your behavior. Personalization complements search. Search requires people to explicitly provide a query. Personalization surfaces useful information without any explicit query.
Personalization can also be used as a way to improve search. For example, if people are repeatedly refining a query (e.g. [greg linden findory], then [greg linden amazon]), they are not finding what they need. Paying attention to what they have done, especially what they have done recently, and showing different search results to different people can help surface information that otherwise might be buried deep. That is also personalization.
In addition, personalization can be used to improve advertising. Almost all advertising is useless, and annoying. Advertising does not have to be that way. Advertising can be useful information about products and services you might actually want. By paying closer attention to your interests and needs, advertising can be targeted instead of sprayed. It can be relevant and helpful, not irrelevant and wasteful. That is also personalization.
Back when I became really interested in this and wanted to work on it, I was just getting out of Stanford in 2003. Creating a company was not my first plan. I talked to Google, Yahoo, MSN, and Amazon first. The people I talked to expressed interest, but not urgency, and did not want to move as aggressively on personalization as I did.
I believed in the value of applying personalization to information. I wanted to see it happen. While I thought it was inevitable that everyone will be doing personalization of information over the next 5-10 years, I wanted to see it sooner. I started Findory to make it happen.
The fundamental idea behind Findory is to apply personalization to information. Help people deal with information overload. Help cut through the noise and filter up the good stuff. Help people find what they need.
Personalization can do this using implicit information about your wants and needs, learning from your behavior. Personalization complements search. Search requires people to explicitly provide a query. Personalization surfaces useful information without any explicit query.
Personalization can also be used as a way to improve search. For example, if people are repeatedly refining a query (e.g. [greg linden findory], then [greg linden amazon]), they are not finding what they need. Paying attention to what they have done, especially what they have done recently, and showing different search results to different people can help surface information that otherwise might be buried deep. That is also personalization.
In addition, personalization can be used to improve advertising. Almost all advertising is useless, and annoying. Advertising does not have to be that way. Advertising can be useful information about products and services you might actually want. By paying closer attention to your interests and needs, advertising can be targeted instead of sprayed. It can be relevant and helpful, not irrelevant and wasteful. That is also personalization.
Back when I became really interested in this and wanted to work on it, I was just getting out of Stanford in 2003. Creating a company was not my first plan. I talked to Google, Yahoo, MSN, and Amazon first. The people I talked to expressed interest, but not urgency, and did not want to move as aggressively on personalization as I did.
I believed in the value of applying personalization to information. I wanted to see it happen. While I thought it was inevitable that everyone will be doing personalization of information over the next 5-10 years, I wanted to see it sooner. I started Findory to make it happen.
Google: Why would anyone ever leave?
Jade Chang at Metropolis Magazine has a fun article on the work environment at Google. An excerpt:
By the way, it is fun to bump into Corin Anderson again. Corey was at University of Washington in the PhD program (he finished, I did not) in computer science around the same time I was. He started in graphics and then did some interesting research work in personalization.
[via Matt Marshall]
Corin Anderson does not work like most of the world: his office is a glass tent, which he shares with two other people. His desk hides behind a complex Rube Goldberg-esque maze, built by Anderson out of a toy called the Chaos Tower, a sort of theme park for marbles.Beautiful. Why would anyone ever leave?
Each day he sits in the midst of figurines, Legos, and stuffed animals, eyes fixed on his computer screen and earphones strapped on, for hours at a stretch. When he wants a snack, he walks to the fully stocked micro-kitchen, maybe breaking open a bag of organic potato chips or grabbing a handful of trail mix. Twenty percent of the time -- with his employer's full approval -- he works on projects of his own devising that are only tangentially related to his job.
And strangest of all, come nightfall he often has no desire to go home, preferring to get dinner, gratis, in one of the employee cafes.
By the way, it is fun to bump into Corin Anderson again. Corey was at University of Washington in the PhD program (he finished, I did not) in computer science around the same time I was. He started in graphics and then did some interesting research work in personalization.
[via Matt Marshall]
When is old news no news?
Noam Cohen at the NYT reports:
If old news is news, there is a question of how you help people find the good stuff. How can we surface interesting, older articles on each reader's front page?
Looking at that, Neil Budde has an interesting quote in the article about personalized news:
Either way, it is interesting to see that Yahoo News wants to show different people different news stories based on their behavior.
When does new news become old news?I am in the latter group. I think it is surprising that more than half of the time an article is read, it is being read more than 36 hours after it was published. It seems that old news is news after all.
In the case of a news article on the Internet, the answer is surprisingly long: 36 hours on average .... More precisely, 36 hours is the amount of time it takes for half of the total readership of an article to have read it.
Traditional ideas about the way people use the Internet would have led researchers to expect a much shorter half-life, more like two to four hours.
"You can spin it two ways," said Dr. Barabasi, a specialist on complex networks. "Gee, only 36 hours is the typical half-life of an article. Or gee, I would have expected it to be shorter."
If old news is news, there is a question of how you help people find the good stuff. How can we surface interesting, older articles on each reader's front page?
Looking at that, Neil Budde has an interesting quote in the article about personalized news:
Neil F. Budde, general manager of Yahoo News, said his site must balance a variety of competing interests: frequent visitors who get bored by even slightly stale news, less frequent visitors who won't know what has happened in the last few hours or even days, and the editors' own news judgment.It is not clear, Neil may only be talking about personalization based on your last visit, offering some older articles if you have not visited in a while. Or, perhaps Neil is going a step further and suggesting that Yahoo News should penalize articles you have seen before and recommend new articles based on what you have read.
"What would be ideal would be to keep track of when you were last on our site and present a package of news that would be different than what others see."
Either way, it is interesting to see that Yahoo News wants to show different people different news stories based on their behavior.
Sunday, July 16, 2006
Starting Findory: The series
I lot of people seemed to enjoy my "Early Amazon" series of posts where I told stories about my early days at Amazon.com.
I thought I might begin another series, "Starting Findory", where I will talk about my experience starting Findory.com.
The series will be wide ranging. I will talk about why I started Findory. I will discuss my decision to build Findory on the cheap and whether that was a good idea. I will ramble on about legal goo and the joy of lawyers. I will write about launching products quickly, building teams, pursuing VC funding, talking to big companies about partnerships, marketing, customer service, and much more.
Not only will it be interesting for me to reanalyze my decisions and get feedback on my conclusions, but also I suspect many would enjoy the read and would find useful tidbits for their own entrepreneurial adventures.
I hope you enjoy it!
Update: I should add that if there is anything in particular you would like me to cover in this series, please let me know and I will see if I can include it.
I thought I might begin another series, "Starting Findory", where I will talk about my experience starting Findory.com.
The series will be wide ranging. I will talk about why I started Findory. I will discuss my decision to build Findory on the cheap and whether that was a good idea. I will ramble on about legal goo and the joy of lawyers. I will write about launching products quickly, building teams, pursuing VC funding, talking to big companies about partnerships, marketing, customer service, and much more.
Not only will it be interesting for me to reanalyze my decisions and get feedback on my conclusions, but also I suspect many would enjoy the read and would find useful tidbits for their own entrepreneurial adventures.
I hope you enjoy it!
Update: I should add that if there is anything in particular you would like me to cover in this series, please let me know and I will see if I can include it.
Wednesday, July 12, 2006
Metcalfe's Law overestimates value
An article in the July 2006 IEEE Spectrum, "Metcalfe's Law is Wrong", convincingly argues that the value of a social network of size n is n log(n), not n^2.
Some carefully selected excerpts:
By the way, the authors also have a fun bit in the article about the advantage Amazon.com and other online stores have over traditional stores:
Some carefully selected excerpts:
Of all the popular ideas of the Internet boom, one of the most dangerously influential was Metcalfe's Law. Simply put, it says that the value of a communications network is proportional to the square of the number of its users.Well worth reading if you were ever a fan of Metcalfe's Law.
The foundation of his eponymous law is the observation that in a communications network with n members, each can make (n-1) connections with other participants. If all those connections are equally valuable ... the total value of the network is ... roughly n ^ 2.
We propose, instead, that the value of a network of size n grows in proportion to n log(n).
The fundamental flaw underlying ... Metcalfe's [Law] is in the assignment of equal value to all connections or all groups .... In fact, in large networks, such as the Internet ... most are not used at all. So assigning equal value to all of them is not justified.
This is our basic objection to Metcalfe's Law, and it's not a new one: it has been noted by many observers, including Metcalfe himself.
If Metcalfe's Law were true, it would create overwhelming incentives for all networks relying on the same technology to merge ... These incentives would make isolated networks hard to explain .... Yet historically there have been many cases of networks that resisted interconnection for a long time.
Further ... if Metcalfe's Law were true, then two networks ought to interconnect regardless of their relative sizes. But in the real world of business and networks, only companies of roughly equal size are ever eager to interconnect. In most cases, the larger network believes it is helping the smaller one far more than it itself is being helped ... The larger network demands some additional compensation before interconnecting. Our n log(n) assessment of value is consistent with this real-world behavior of networking companies; Metcalfe's n ^ 2 is not.
We have, as well, developed several quantitative justifications for our n log(n) rule-of-thumb valuation of a general communications network of size n. The most intuitive one is based on yet another rule of thumb, Zipf's Law .... To understand how Zipf's Law leads to our n log(n) law, consider the relative value of a network near and dear to you -- the members of your e-mail list. Obeying, as they usually do, Zipf's Law, the members of such networks can be ranked .... [The] total value to you will be the sum of the decreasing 1/k values of all the other members of the network.
By the way, the authors also have a fun bit in the article about the advantage Amazon.com and other online stores have over traditional stores:
Incidentally, this mathematics indicates why online stores are the only place to shop if your tastes in books, music, and movies are esoteric. Let's say an online music store like Rhapsody or iTunes carries 735 000 titles, while a traditional brick-and-mortar store will carry 10 000 to 20 000. The law of long tails says that two-thirds of the online store's revenue will come from just the titles that its physical rival carries. In other words, a very respectable chunk of revenue -- a third -- will come from the 720 000 or so titles that hardly anyone ever buys. And, unlike the cost to a brick-and-mortar store, the cost to an online store of holding all that inventory is minimal. So it makes good sense for them to stock all those incredibly slow-selling titles.[via Paul Kedrosky]
Tuesday, July 11, 2006
Personalized search at SIGIR 2006
Update: My post is wrong, including the title. The first author of the paper, Eugene, contacted me to let me know I had misinterpreted the work.
This research work extends the use of document features in some earlier work on RankNet with new "user action" features.
However, every searcher sees the same search results in the system. Eugene said that "personalization is a very interesting direction for future research," but that this system "does not do personalization."
I apologize. I was too quick to link this paper with some of Susan Dumais' other work.
Original post:
Microsoft researchers Eugene Agichtein, Eric Brill, and Susan Dumais have a paperon personalized search, "Improving Web Search Ranking by Incorporating User Behavior Information" (PDF), at the upcoming SIGIR 2006 conference.
The paper reports some good successes with reordering search results based oneach searcher's clickstreams:The basic idea is keep a history of clicked results for each searcher, learn which document features each searcher seems to prefer, and then bias the search results toward those features.
In table 6.1 in the paper, there is one result I find particular interesting. They got a lot of lift merely from increasing the rank of any document on which the searcher clicked in the past (referred to as "BM25F-RerankCT"). That is, without learning a user model at all, it helps quite a bit to simply favor what the searcher clicked on before.
Most of the paper focuses its time on methods for learning which document features are most of interest to a given searcher. It is a complicated approach that, I suspect, will struggle against the problems of sparse data and over-generalization.
Given the success of just increasing the rank of anything I clicked on before, I would be interested in seeing more of a social filtering approach. They already increase the rank of search results I clicked on. Now, also increase the rank of search results people like me clicked on. Help me find what I need using what others have found.
By the way, if you like this MSR paper, you might also be interested in another paper by the same authors to appear at the same conference, "Learning User Interaction Models for Predicting Web Search Result Preferences" (PDF).That other paper spends more time on learning what document features a searcher seems to like as well as exploring some ideas around reranking search results around a previously clicked search result.
This research work extends the use of document features in some earlier work on RankNet with new "user action" features.
However, every searcher sees the same search results in the system. Eugene said that "personalization is a very interesting direction for future research," but that this system "does not do personalization."
I apologize. I was too quick to link this paper with some of Susan Dumais' other work.
Original post:
Microsoft researchers Eugene Agichtein, Eric Brill, and Susan Dumais have a paper
The paper reports some good successes with reordering search results based on
We show that incorporating user behavior data can significantly improve ordering of top results in real web search setting.
We show that incorporating implicit feedback can augment other features, improving the accuracy of a competitive web search ranking algorithms by as much as 31% relative to the original performance.
The general approach is to re-rank the results obtained by a web search engine according to observed clickthrough and other user interactions for the query in previous search sessions. Each result is assigned a score according to expected relevance/user satisfaction based on previous interactions.
In table 6.1 in the paper, there is one result I find particular interesting. They got a lot of lift merely from increasing the rank of any document on which the searcher clicked in the past (referred to as "BM25F-RerankCT"). That is, without learning a user model at all, it helps quite a bit to simply favor what the searcher clicked on before.
Most of the paper focuses its time on methods for learning which document features are most of interest to a given searcher. It is a complicated approach that, I suspect, will struggle against the problems of sparse data and over-generalization.
Given the success of just increasing the rank of anything I clicked on before,
By the way, if you like this MSR paper, you might also be interested in another paper by the same authors to appear at the same conference, "Learning User Interaction Models for Predicting Web Search Result Preferences" (PDF).
Community, content, and the lessons of the Web
The World Wide Web is an enormous pool of community-generated content. People everywhere and anywhere can write a web page and add it to the Web.
Recently, there have been more and more attempts to build playgrounds of user-generated content. These sites are built around tools that make it easy to create content than writing an HTML page and often have constraints on the purpose or the type of content. Examples include Wikipedia, Yahoo Answers, My Space, YouTube, and the various weblog creation and searching tools.
When looking at the future of these new community-generated content sandboxes, it is useful to look at the experience of the Web as a whole. In the idealistic early 1990's, all websites tended to be academic and useful. There was little point of doing anything else. A smattering of geeks at universities were the only users of the fledging World Wide Web.
As the Web grew, so did the profit motive. More people were on the web, so there was more money to be made if a fraction of Web users could be fooled. Junk started to appear.
Today, the greatest pool of user-generated content ever created, the World Wide Web, is full of crap and spam. Search engines or other applications that seeks to get value from the Web needs to be built with filtering in mind. The Web is a cesspool, but sufficiently powerful tools can pluck gems from the sea of goo.
Now, many are building their own playgrounds for community-generated content, miniature versions of the World Wide Web. As the experience of the Web shows, we cannot expect the crowds to selflessly combine their skills and knowledge to deliver wisdom, not once the sites attract the mainstream. Profit motive combined with indifference will swamp the good under a pool of muck. To survive, the goal will have to shift from gathering content to uncovering good content.
The experience of the World Wide Web as a whole should serve as a lesson to those building the next generation of community-powered websites. At scale, it is no longer about aggregating knowledge, it is about filtering crap. We need seek the signal in the noise and pull the wisdom from the din.
Recently, there have been more and more attempts to build playgrounds of user-generated content. These sites are built around tools that make it easy to create content than writing an HTML page and often have constraints on the purpose or the type of content. Examples include Wikipedia, Yahoo Answers, My Space, YouTube, and the various weblog creation and searching tools.
When looking at the future of these new community-generated content sandboxes, it is useful to look at the experience of the Web as a whole. In the idealistic early 1990's, all websites tended to be academic and useful. There was little point of doing anything else. A smattering of geeks at universities were the only users of the fledging World Wide Web.
As the Web grew, so did the profit motive. More people were on the web, so there was more money to be made if a fraction of Web users could be fooled. Junk started to appear.
Today, the greatest pool of user-generated content ever created, the World Wide Web, is full of crap and spam. Search engines or other applications that seeks to get value from the Web needs to be built with filtering in mind. The Web is a cesspool, but sufficiently powerful tools can pluck gems from the sea of goo.
Now, many are building their own playgrounds for community-generated content, miniature versions of the World Wide Web. As the experience of the Web shows, we cannot expect the crowds to selflessly combine their skills and knowledge to deliver wisdom, not once the sites attract the mainstream. Profit motive combined with indifference will swamp the good under a pool of muck. To survive, the goal will have to shift from gathering content to uncovering good content.
The experience of the World Wide Web as a whole should serve as a lesson to those building the next generation of community-powered websites. At scale, it is no longer about aggregating knowledge, it is about filtering crap. We need seek the signal in the noise and pull the wisdom from the din.
Saturday, July 08, 2006
Personalization and reinventing bbc.co.uk
The BBC recently ran a contest to redesign the BBC home page.
Many of the entries feature implicit personalization. For example, the design notes for the winner of the contest say:
Several of the runners-up also envision an automatically and implicitly personalized page for the BBC.
It is interesting to see widespread interest for implicit personalization for major portals like the BBC. Perhaps we might even get Yahoo to do it?
Many of the entries feature implicit personalization. For example, the design notes for the winner of the contest say:
...Here is a direct link to a thumbnail image of the winning design.
3) Being able to personalize around your interests.
...
5) Finding people with similar interests.
...
9) Slanting the bias of the page towards the user and his content, his world in the BBC.
...
Several of the runners-up also envision an automatically and implicitly personalized page for the BBC.
It is interesting to see widespread interest for implicit personalization for major portals like the BBC. Perhaps we might even get Yahoo to do it?
Thursday, July 06, 2006
Yahoo building a Google FS clone?
The Hadoop open source project is building a clone of the powerful Google cluster tools Google File System and MapReduce.
I was curious to see how much Yahoo appears to be involved in Hadoop. Doug Cutting, the primary developer of Lucene, Nutch, and Hadoop, is now working for Yahoo but, at the time, that hiring was described as supporting an independent open source project.
Digging further, it seems Yahoo's role is more complicated. Browsing through the Hadoop developers mailing list, I can see that more than a dozen people from Yahoo appear to be involved in Hadoop.
In some cases, the involvement is deep. One of the Yahoo developers, Konstantin Shvachko, produced a detailed requirement document for Hadoop. The document appears to lay out what Yahoo needs from Hadoop, including such tidbits as handling 10k+ nodes, 100k simultaneous clients, and 10 petabytes in a cluster.
Also noteworthy is Eric Baldeschwieler, a director of software development at Yahoo, who recently talked about direct support from Yahoo for Hadoop. Eric said, "How we are going to establish a testing / validation regime that will support innovation ... We'll be happy to help staff / fund such a testing policy."
There is nothing wrong with this, of course. If anything, it should be viewed as noble that Yahoo is supporting an open source version of these powerful tools and making them available to all.
But it is interesting. It is interesting that Yahoo is so involved in building a Google FS and MapReduce clone. It is interesting that Yahoo would choose to open source these tools. It is interesting to see this level of involvement from Yahoo in Hadoop.
I was curious to see how much Yahoo appears to be involved in Hadoop. Doug Cutting, the primary developer of Lucene, Nutch, and Hadoop, is now working for Yahoo but, at the time, that hiring was described as supporting an independent open source project.
Digging further, it seems Yahoo's role is more complicated. Browsing through the Hadoop developers mailing list, I can see that more than a dozen people from Yahoo appear to be involved in Hadoop.
In some cases, the involvement is deep. One of the Yahoo developers, Konstantin Shvachko, produced a detailed requirement document for Hadoop. The document appears to lay out what Yahoo needs from Hadoop, including such tidbits as handling 10k+ nodes, 100k simultaneous clients, and 10 petabytes in a cluster.
Also noteworthy is Eric Baldeschwieler, a director of software development at Yahoo, who recently talked about direct support from Yahoo for Hadoop. Eric said, "How we are going to establish a testing / validation regime that will support innovation ... We'll be happy to help staff / fund such a testing policy."
There is nothing wrong with this, of course. If anything, it should be viewed as noble that Yahoo is supporting an open source version of these powerful tools and making them available to all.
But it is interesting. It is interesting that Yahoo is so involved in building a Google FS and MapReduce clone. It is interesting that Yahoo would choose to open source these tools. It is interesting to see this level of involvement from Yahoo in Hadoop.
Baseline on "How Google Works"
David Carr at Baseline Magazine wrote a long article on Google called "How Google Works".
It is an interesting summary that links together a bunch of information buried in a lot of sources. As David said near the start of the article:
Make sure to clickthrough on the "Next" link on each page so you see the entire article. It's 14 pages long. If you want it all on one page, the printer-friendly version is here.
It is an interesting summary that links together a bunch of information buried in a lot of sources. As David said near the start of the article:
Google has a split personality when it comes to questions about its back-end systems. To the media, its answer is, "Sorry, we don't talk about our infrastructure."I am briefly quoted on the second page of the article, unfortunately nothing particularly insightful.
Yet, Google engineers crack the door open wider when addressing computer science audiences, such as rooms full of graduate students whom it is interested in recruiting.
As a result, sources for this story included technical presentations available from the University of Washington Web site, as well as other technical conference presentations, and papers published by Google's research arm, Google Labs.
Make sure to clickthrough on the "Next" link on each page so you see the entire article. It's 14 pages long. If you want it all on one page, the printer-friendly version is here.
Wednesday, July 05, 2006
Findory traffic Q2 2006
I have posted graphs of the traffic for Findory.com every quarter for the last couple years ([1] [2] [3] [4] [5] [6]). As you can see from those previous posts, for the first two years, Findory had rapid, exponential growth.
The Q2 2006 numbers are in. Unfortunately, the growth Findory has seen in the past has stalled.
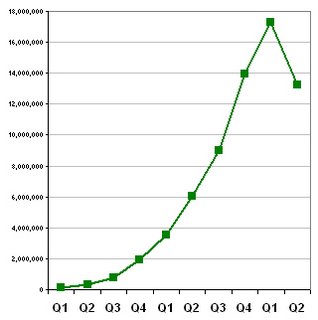
Frankly, it is hard to describe this as anything short of dismal. Not only did traffic drop in Q2 2006, it dropped slightly below the level of Q4 2005. I am very disappointed.
What was the reason for the drop? A major factor appears to be a large decline in referrals from other web sites. In particular, traffic to and through Findory Inline and Findory's RSS feeds and API decreased by 30-40% this quarter. Referrals from search engines (e.g. Google, MSN, Yahoo) also dropped by about 30%.
The surprising thing about these numbers is that they come at a quarter when Findory had some remarkable successes. In this quarter, Findory was mentioned in the Wall Street Journal and in PC World (excerpts on the Findory Press page). Findory even was compared favorably to Google News ("[Google's] recommendation engine seems less intelligent and transparent than Findory's" -- PC World), a remarkable achievement for a tiny startup.
Also in this quarter, Findory launched a new interface, Findory Mobile, that delivers a personalized selection of news and weblog headlines to your mobile phone. Findory Mobile is the only news site designed for mobile devices that selects and recommends articles based on the articles you read on your phone.
And, just a few weeks ago, Findory launched Findory Podcasts and Findory Video. While there are other directories of podcasts, Findory Podcasts is the only one that recommends podcasts based on what you listen to. Findory Video recommends videos by paying attention to what videos you watch, taming the usual sea of crud you see on YouTube and Google Video by surfacing videos that are likely to be of interest.
Looking forward to the next quarter, I plan on focusing on expanding Findory's crawl in all product lines and making iterative improvements to the personalization in the newer features: podcasts, video, mobile, web search, and advertising.
Although it is a frequent requests from Findory readers, I am afraid Findory will not be able to offer support for non-English languages, mostly because of the cost of adapting the analyses supporting Findory's personalization to non-English languages. As much as I would like to expand internationally, Findory is a tiny, self-funded company, and it cannot bear the cost.
The latest traffic numbers are disappointing, but Findory's mission remains unchanged. Information overload must be tamed. We must seek relevancy. The useful and interesting must be surfaced. Findory will help personalize information.
The Q2 2006 numbers are in. Unfortunately, the growth Findory has seen in the past has stalled.
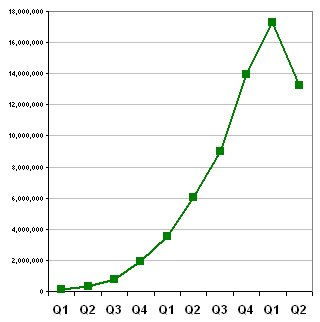
Frankly, it is hard to describe this as anything short of dismal. Not only did traffic drop in Q2 2006, it dropped slightly below the level of Q4 2005. I am very disappointed.
What was the reason for the drop? A major factor appears to be a large decline in referrals from other web sites. In particular, traffic to and through Findory Inline and Findory's RSS feeds and API decreased by 30-40% this quarter. Referrals from search engines (e.g. Google, MSN, Yahoo) also dropped by about 30%.
The surprising thing about these numbers is that they come at a quarter when Findory had some remarkable successes. In this quarter, Findory was mentioned in the Wall Street Journal and in PC World (excerpts on the Findory Press page). Findory even was compared favorably to Google News ("[Google's] recommendation engine seems less intelligent and transparent than Findory's" -- PC World), a remarkable achievement for a tiny startup.
Also in this quarter, Findory launched a new interface, Findory Mobile, that delivers a personalized selection of news and weblog headlines to your mobile phone. Findory Mobile is the only news site designed for mobile devices that selects and recommends articles based on the articles you read on your phone.
And, just a few weeks ago, Findory launched Findory Podcasts and Findory Video. While there are other directories of podcasts, Findory Podcasts is the only one that recommends podcasts based on what you listen to. Findory Video recommends videos by paying attention to what videos you watch, taming the usual sea of crud you see on YouTube and Google Video by surfacing videos that are likely to be of interest.
Looking forward to the next quarter, I plan on focusing on expanding Findory's crawl in all product lines and making iterative improvements to the personalization in the newer features: podcasts, video, mobile, web search, and advertising.
Although it is a frequent requests from Findory readers, I am afraid Findory will not be able to offer support for non-English languages, mostly because of the cost of adapting the analyses supporting Findory's personalization to non-English languages. As much as I would like to expand internationally, Findory is a tiny, self-funded company, and it cannot bear the cost.
The latest traffic numbers are disappointing, but Findory's mission remains unchanged. Information overload must be tamed. We must seek relevancy. The useful and interesting must be surfaced. Findory will help personalize information.
Monday, July 03, 2006
Combating web spam with personalization
In a BBC article by Darren Waters, Google Engineering VP Douglas Merrill says of web spam:
One way to reduce the value is to catch as much spam as possible and eliminate it. This reduces the average value from spamming, but the lucky few who get through the filter continue to receive a massive payoff.
Another way to reduce the value is to reduce the maximum payoff. If different people see different search results, spamming becomes much less attractive. The jackpot from getting to the top of the page disappears. A successful spam link will be shown to millions, not billions.
Personalized search shows different search results to different people based on their history and their interests. Not only does this increase the relevance of the search results, but also it makes the search results harder to spam.
This problem is not unique to web search. For example, Digg, a site that produces a list of popular weblog articles, offers an attractive target for spammers. If Digg could offer different lists for different people, perhaps showing "most popular for people like me", it would reduce the incentive to try to manipulate the site to get to the top of the page.
In general, anywhere we show the same list to millions of people, we create an incentive to manipulate the list. We can reduce that incentive by filtering spam. We can also reduce that incentive by not showing the same list to millions of people, instead showing different lists to different people based on their interests. The incentive to spam fades, fragmented into a complex nest of personalized choices.
"Spam is an arms race," said Mr Merrill, adding it was a multi-million dollar industry which was trying to fool search engines.There is a huge amount of value from getting to the top of the search results. If spammers get their links to the top of the page, billions will see it.
Spammers exploit the way search engines work by bombarding blogs and comments pages with links to their websites. Google prioritizes websites in their search results if a particular page is linked to by other sites.
Mr Merrill said: "Spammers are highly motivated. There is a lot of money at stake."
One way to reduce the value is to catch as much spam as possible and eliminate it. This reduces the average value from spamming, but the lucky few who get through the filter continue to receive a massive payoff.
Another way to reduce the value is to reduce the maximum payoff. If different people see different search results, spamming becomes much less attractive. The jackpot from getting to the top of the page disappears. A successful spam link will be shown to millions, not billions.
Personalized search shows different search results to different people based on their history and their interests. Not only does this increase the relevance of the search results, but also it makes the search results harder to spam.
This problem is not unique to web search. For example, Digg, a site that produces a list of popular weblog articles, offers an attractive target for spammers. If Digg could offer different lists for different people, perhaps showing "most popular for people like me", it would reduce the incentive to try to manipulate the site to get to the top of the page.
In general, anywhere we show the same list to millions of people, we create an incentive to manipulate the list. We can reduce that incentive by filtering spam. We can also reduce that incentive by not showing the same list to millions of people, instead showing different lists to different people based on their interests. The incentive to spam fades, fragmented into a complex nest of personalized choices.
NYT on the Google cluster
Saul Hansell and John Markoff at the NYT look at Google's cluster. Some excerpts:
See also my previous post, "Microsoft is building a Google cluster", where I said, "Microsoft is trying to build a Google-sized cluster, belatedly recognizing that massive computing resources are major force multipliers for those who have them and an insurmountable barrier for those that do not."
See also Paul Kedrosky's summary of the Hansell and Markoff NYT article. Don't miss the comments on Paul's post.
"Google is as much about infrastructure as it is about the search engine," said Martin Reynolds, an analyst with the Gartner Group. "They are building an enormous computing resource on a scale that is almost unimaginable."See also Google's publications on Sawzall, MapReduce, Google File System, and the Google cluster.
The central tenet of [Google's] strategy is that its growing cadre of world-class computer scientists can design a network of machines that can store and process more information more efficiently than anyone else.
"We don't think our competitors can deploy systems cheaper, faster or at scale," Alan Eustace, Google's vice president for research and systems engineering.
"Nobody builds servers as unreliably as we do," [Urs] Holzle [Google Operations SVP] .... "Having lots of relatively unreliable machines and turning them into a reliable service is a hard problem ... That is what we have been doing for a while."
See also my previous post, "Microsoft is building a Google cluster", where I said, "Microsoft is trying to build a Google-sized cluster, belatedly recognizing that massive computing resources are major force multipliers for those who have them and an insurmountable barrier for those that do not."
See also Paul Kedrosky's summary of the Hansell and Markoff NYT article. Don't miss the comments on Paul's post.
Subscribe to:
Posts (Atom)

{kind=link}