I have been playing with Wallop, a social networking startup spun out of Microsoft Research, for a couple days now. So far, I am underwhelmed.
First, I have to admit, I am in no way in their target demographic. I am too old and boring, and my dating days are way behind me.
That being said, Wallop looks like a confusing mess to me. The entire site is a giant Flash app with a non-standard and non-intuitive user interface. There are menus and buttons scattered everywhere, but most of them don't do what you want; right-clicking is the primary way of taking action. Everything is rounded, buttons, menus, pictures, everything.
All this stuff is supposed to be hip, I guess. To me, it is just befuddling.
The default view when you first go to Wallop is your "profile", which is just a blob of text. In a circular pattern around that, there is a picture of yourself, a menu bar with a bunch of buttons that are effectively tabs for changing what is displayed, and then little windows around that show you a subset of the content from the tabs (e.g. the title of one of your uploaded MP3s).
The focus on Wallop seems to be on sharing pictures and music. They prominently feature a toolbar for playing uploaded MP3s. There are also communication tools for use inside of Wallop, a messaging system titled "Conversations" and a weblog.
There does seem to be a lot of potential for lurking and ad hoc communication. For example, I can pick people I don't know, look at all their public photos (which is the default setting when you upload photos) and comment on any one I want. In general, it appears you can tag or comment on about any item on Wallop.
There seems to me much less emphasis on the network than on other sites. The network tab shows people in a circular pattern radiating out from you. Looking at friend-of-a-friend relationships seemed slow and cumbersome. I could not find a way to search the network for people I know.
So far, I'm not sure what the appeal would be. It's confusing, cumbersome, not useful, and not fun. I don't get it.
See also my previous post on Wallop, "Microsoft's new Wallop startup", that includes links to academic papers on Wallop published while it was still at Microsoft Research.
See also Kari Lynn Dean's 2003 Wired article on Wallop, "Will Microsoft Wallop Friendster?".
Friday, September 29, 2006
Thursday, September 28, 2006
WebSpam talk and SIMS 141 speakers
I really enjoyed this "WebSpam" (link is correct, talk is mislabeled on Google Video) talk by Marc Najork from Microsoft Research.
It covers a lot of the techniques for web spam, examples of their tricks, spammer's motivations, and some of the countermeasures. Light and fun. Slides from the talk (PDF) are also available.
This talk is from Marti Hearst's SIMS 141 Fall 2005 class at UC Berkeley. There are slides and videos from many other talks available on that page. She had a remarkable set of speakers that included Jan Pedersen, Daniel Rose, Susan Dumais, Peter Norvig, Sep Kamvar, Bradley Horowitz, John Battelle, and Sergey Brin.
The quality of the videos on the SIMS 141 course page is low. There are higher quality videos for some of the talks on Google Video. A few of these talks on Google Video appear to be mislabeled; look at the comments at the bottom of the page to get the right titles.
Of the other talks, I particularly enjoyed "User Experience Issues in Web Search" by Daniel Rose from Yahoo Search. Peter Norvig's talk was also a lot of fun, but the low quality of the video available from the SIMS 141 page keeps me from recommending it. Finally, if you haven't looked at the Stuff I've Seen desktop search project from Microsoft Research, definitely look over the slides (PDF) from Susan Dumais' talk.
Unfortunately, Sep Kamvar's SIMS 141 talk on search personalization at Google appears to have not been recorded. Darn. I very much would have liked to see that.
Marc Najork also was at SIGIR AIRWeb 2006. I wrote up some notes on one particularly interesting discussion that involved Marc and many others. I also have other notes on the short presentation I did at that workshop.
On the Stuff I've Seen project at Microsoft Research, please also see some of my previous posts on that project, including "Using the desktop to improve search", "Finding and discovering", and Google Memex".
Thanks to Nathan Weinberg for reminding me to go back to the SIMS 141 page and mentioning the Google Video versions of some of the talks. Thanks to Danny Sullivan for originally pointing out the videos and slides available from the SIMS 141 page. And, thank you, Professor Marti Hearst, for making this remarkable content from your class available to all of us.
Update: The titles on the copies of the talks on Google Video have been fixed. They are now all correct.
It covers a lot of the techniques for web spam, examples of their tricks, spammer's motivations, and some of the countermeasures. Light and fun. Slides from the talk (PDF) are also available.
This talk is from Marti Hearst's SIMS 141 Fall 2005 class at UC Berkeley. There are slides and videos from many other talks available on that page. She had a remarkable set of speakers that included Jan Pedersen, Daniel Rose, Susan Dumais, Peter Norvig, Sep Kamvar, Bradley Horowitz, John Battelle, and Sergey Brin.
The quality of the videos on the SIMS 141 course page is low. There are higher quality videos for some of the talks on Google Video. A few of these talks on Google Video appear to be mislabeled; look at the comments at the bottom of the page to get the right titles.
Of the other talks, I particularly enjoyed "User Experience Issues in Web Search" by Daniel Rose from Yahoo Search. Peter Norvig's talk was also a lot of fun, but the low quality of the video available from the SIMS 141 page keeps me from recommending it. Finally, if you haven't looked at the Stuff I've Seen desktop search project from Microsoft Research, definitely look over the slides (PDF) from Susan Dumais' talk.
Unfortunately, Sep Kamvar's SIMS 141 talk on search personalization at Google appears to have not been recorded. Darn. I very much would have liked to see that.
Marc Najork also was at SIGIR AIRWeb 2006. I wrote up some notes on one particularly interesting discussion that involved Marc and many others. I also have other notes on the short presentation I did at that workshop.
On the Stuff I've Seen project at Microsoft Research, please also see some of my previous posts on that project, including "Using the desktop to improve search", "Finding and discovering", and Google Memex".
Thanks to Nathan Weinberg for reminding me to go back to the SIMS 141 page and mentioning the Google Video versions of some of the talks. Thanks to Danny Sullivan for originally pointing out the videos and slides available from the SIMS 141 page. And, thank you, Professor Marti Hearst, for making this remarkable content from your class available to all of us.
Update: The titles on the copies of the talks on Google Video have been fixed. They are now all correct.
Wednesday, September 27, 2006
Potential of web search personalization
There are some great data points on the potential of personalized web search in a KDD 2006 paper, "A Large-Scale Analysis of Query Logs for Assessing Personalization Opportunities", by Steve Wedig and Omid Madani from Yahoo Research.
The paper starts with what should by now be a familiar-sounding motivation for personalized search:
Right at the beginning, the authors distinguish between using a searcher's short-term history to change search results, which they call "adjustment", and modifying searcher results using a profile built from their long-term history, which they refer to as "personalization".
Frequent readers of this weblog would know that I would call the first personalization and the second "probably not worth doing". But this paper does a good job quantifying the potential impact of both the short-term and long-term approaches to personalized search.
In particular, the authors looked at the number of searchers who had enough information for profiles built from long-term history. In their analysis, 50% of queries to Yahoo Search came from "users who performed at least 100 queries over the 6 month period." That seems promising.
However, later in the paper, they analyze the number of queries necessary for a user's interests to clearly converge and become distinct from the population as a whole. They determined it required "a few hundred queries". Less than 25% of queries and less than 3% of users appeared to have that much data.
This does not mean that a long-term, profile-based approach to personalization is not worth doing, but it does mean that it would only impact a minority of the queries and users.
The short-term approach, which they call "adjustment", appears to have potential to influence many queries. The researchers talk a bit about some promising approaches for that in the last part of the paper, including focusing on less common clickthroughs, clickthroughs that users tend to return to, and related clickthroughs. They claim that "with short-term adjustment, a single click ... could dramatically improve results for the rest of your search, even without any prior user history."
In the end, it is probably worth doing both approaches, but this paper is useful for understanding some of the limitations of each. Well worth reading.
For more on personalized web search, please also see some of my previous posts: "Beyond the commons: Personalized web search", " Google Personalized Search and Bigtable", " More on Google personalized search", and " New personalized web search at Findory".
By the way, if you like this post, you may also be interested in my post, "Recommending advertisements", on another of Omid Madani's papers.
Update: If you have trouble downloading the paper from Yahoo Research, you can also get it from the ACM.
The paper starts with what should by now be a familiar-sounding motivation for personalized search:
Interacting with search engines has traditionally been an impersonal affair, with the returned results a function only of the query entered.To determine the potential for personalized search, the researchers analyzed "six months of query logs from the Yahoo! search engine" that "contained about 1.35 million cookies, 26 million searches, and 20 million clicks." Their goal was to determine "the extent of short and long term history available" and the "consistency and convergence rate" of user's interests.
Unfortunately the average query length is consistently reported to be around two, so many queries are too short to disambiguate the user's information need. Moreover, users often view only the first page of results, which makes precision critically important.
These limitations have motivated researchers to look beyond the query and consider how a search's context can provide further evidence about the user's information need.
Right at the beginning, the authors distinguish between using a searcher's short-term history to change search results, which they call "adjustment", and modifying searcher results using a profile built from their long-term history, which they refer to as "personalization".
Frequent readers of this weblog would know that I would call the first personalization and the second "probably not worth doing". But this paper does a good job quantifying the potential impact of both the short-term and long-term approaches to personalized search.
In particular, the authors looked at the number of searchers who had enough information for profiles built from long-term history. In their analysis, 50% of queries to Yahoo Search came from "users who performed at least 100 queries over the 6 month period." That seems promising.
However, later in the paper, they analyze the number of queries necessary for a user's interests to clearly converge and become distinct from the population as a whole. They determined it required "a few hundred queries". Less than 25% of queries and less than 3% of users appeared to have that much data.
This does not mean that a long-term, profile-based approach to personalization is not worth doing, but it does mean that it would only impact a minority of the queries and users.
The short-term approach, which they call "adjustment", appears to have potential to influence many queries. The researchers talk a bit about some promising approaches for that in the last part of the paper, including focusing on less common clickthroughs, clickthroughs that users tend to return to, and related clickthroughs. They claim that "with short-term adjustment, a single click ... could dramatically improve results for the rest of your search, even without any prior user history."
In the end, it is probably worth doing both approaches, but this paper is useful for understanding some of the limitations of each. Well worth reading.
For more on personalized web search, please also see some of my previous posts: "Beyond the commons: Personalized web search", " Google Personalized Search and Bigtable", " More on Google personalized search", and " New personalized web search at Findory".
By the way, if you like this post, you may also be interested in my post, "Recommending advertisements", on another of Omid Madani's papers.
Update: If you have trouble downloading the paper from Yahoo Research, you can also get it from the ACM.
Management and incentives at Google
Googler Steve Yegge has some interesting tidbits on Google's management buried in one of his posts. Some extended excerpts:
On Steve's comments about gratitude, see also my earlier post, "Free food at Google", where I said, "Perks can be seen as a gift exchange, having an impact on morale and motivation disproportionate to their cost."
For an interesting comparison to Microsoft, see my July 2004 post, "Microsoft cuts benefits". After the predictable drop in morale and loss of key people from cutting benefits, Microsoft reversed their policy, which I described in my May 2006 post, "Microsoft drops forced rank, increases benefits".
See also some of my other posts about Google's management structure, "First, kill all the managers" and "Google's rules of management".
For a comparison to Amazon, I have a couple posts on their management practices, one critical of "two pizza teams" and one praising some of Amazon's non-monetary rewards.
Update: Dare Obasanjo at Microsoft has a quite different take on all of this: "A company pays you at worst 'what they think they can get away with' and at best 'what they think you are worth', neither of these should inspire gratitude."
Google's process probably does look like chaos ...Beautiful. I love it. I wish I had been able to push things further in this direction when I was at Amazon.
What's to stop engineers from leaving all the trouble projects, leaving behind bug-ridden operational nightmares? What keeps engineers working towards the corporate goals if they can work on whatever they want? How do the most important projects get staffed appropriately?
Google drives behavior through incentives. Engineers working on important projects are, on average, rewarded more than those on less-important projects. You can choose to work on a far-fetched research-y kind of project that may never be practical to anyone, but the work will have to be a reward unto itself. If it turns out you were right and everyone else was wrong (the startup's dream), and your little project turns out to be tremendously impactful, then you'll be rewarded for it. Guaranteed.
The rewards and incentives are too numerous to talk about here, but the financial incentives range from gift certificates and massage coupons up through giant bonuses and stock grants, where I won't define "giant" precisely, but think of Google's scale and let your imagination run a bit wild, and you probably won't miss the mark by much.
Google a peer-review oriented culture, and earning the respect of your peers means a lot there. More than it does at other places, I think. This is in part because it's just the way the culture works; it's something that was put in place early on and has managed to become habitual. It's also true because your peers are so damn smart that earning their respect is a huge deal.
Another incentive is that every quarter, without fail, they have a long all-hands in which they show every single project that launched to everyone, and put up the names and faces of the teams (always small) who launched each one, and everyone applauds. Gives me a tingle just to think about it. Google takes launching very seriously, and I think that being recognized for launching something cool might be the strongest incentive across the company.
The perks are over the top, and the rewards are over the top, and everything there is so comically over the top that you have no choice, as an outsider, but to assume that everything the recruiter is telling you is a baldfaced lie, because there's no possible way a company could be that generous to all of its employees.
The thing that drives the right behavior at Google, more than anything else, more than all the other things combined, is gratitude. You can't help but want to do your absolute best for Google; you feel like you owe it to them for taking such incredibly good care of you.
On Steve's comments about gratitude, see also my earlier post, "Free food at Google", where I said, "Perks can be seen as a gift exchange, having an impact on morale and motivation disproportionate to their cost."
For an interesting comparison to Microsoft, see my July 2004 post, "Microsoft cuts benefits". After the predictable drop in morale and loss of key people from cutting benefits, Microsoft reversed their policy, which I described in my May 2006 post, "Microsoft drops forced rank, increases benefits".
See also some of my other posts about Google's management structure, "First, kill all the managers" and "Google's rules of management".
For a comparison to Amazon, I have a couple posts on their management practices, one critical of "two pizza teams" and one praising some of Amazon's non-monetary rewards.
Update: Dare Obasanjo at Microsoft has a quite different take on all of this: "A company pays you at worst 'what they think they can get away with' and at best 'what they think you are worth', neither of these should inspire gratitude."
Humans and algorithms and humans
John Battelle interviews Googler Matt Cutts. Some interesting excerpts from Matt on algorithms based on user data:
Findory's personalization is like what happens on social networking sites, but all the sharing happens anonymously and implicitly. Findory's algorithms quietly do all the work behind the scenes so that everyone in the Findory community can recommend articles to each other.
Matt also has a quick warning about some of the issue with abuse and spam:
See also my previous post, "Getting the crap out of user-generated content".
When savvy people think about Google, they think about algorithms, and algorithms are an important part of Google. But algorithms aren't magic ... quite often ... [they] are based on human contributions in some way.Findory is similar in that its recommendations are based on what humans find and discover. The knowledge of what is good and what is not comes from readers; it is people sharing what they found with each other.
The simplest example is that hyperlinks on the web are created by people ... Google News ranks based on which stories human editors around the web choose to highlight. Most of the successful web companies benefit from human input, from eBay's trust ratings to Amazon's product reviews and usage data. Or take Netflix's star ratings ... [they] are done by people, and they converge to pretty trustworthy values after only a few votes.
Findory's personalization is like what happens on social networking sites, but all the sharing happens anonymously and implicitly. Findory's algorithms quietly do all the work behind the scenes so that everyone in the Findory community can recommend articles to each other.
Matt also has a quick warning about some of the issue with abuse and spam:
The flip side is that someone has to pay attention to potential abuse by bad actors. Maybe it's cynical of me, but any time people are involved, I tend to think about how someone could abuse the system. We've seen the whole tagging idea in Web 1.0 when they were called meta tags, and some people abused them so badly with deceptive words that to this day, most search engine give little or no scoring weight to keywords in meta tags.See also my previous post, "Community, content, and the lessons of the Web", where I said, "We cannot expect the crowds to selflessly combine their skills and knowledge to deliver wisdom, not once the sites attract the mainstream. Profit motive combined with indifference will swamp the good under a pool of muck ... At scale, it is no longer about aggregating knowledge, it is about filtering crap."
See also my previous post, "Getting the crap out of user-generated content".
Sunday, September 24, 2006
Findory switches from Google to Amazon ads
Findory recently launched a new version of our personalized advertising engine. This new version is based on Amazon Associates rather than Google AdSense.
Like the old engine, the new engine targets based on the content of the page and each reader's clickstream history on Findory. Unlike the old engine, it shows a targeted selection of books from Amazon rather than text ads from Google AdSense.
Why did Findory switch?
AdSense is an intelligent, self-optimizing, ad targeting system. It is a stubborn beast, convinced it knows what is right.
When Findory layered its own intelligent ad targeting system on top of AdSense, the two fought like crazed monkeys.
Findory would tell AdSense, "This page has articles about Google, Yahoo, search, engines, and technology," and then ask Google to target ads. Given that description, what do you think would be reasonable? Probably ads for web search engines and things related to web search engines?
Instead, Google sometimes would respond with ads for aircraft or automobile engines, blindly fixating on the word "engine" and apparently ignoring the rest of the information. It is hard to work with that.
We even tried test cases where we sent them nothing but a single keyword. For example, we said, "This page is about 'Google'." AdSense sometimes responded with ads for get-rich-quick schemes and penny stocks. That may be amusingly ironic. It even may be lucrative. But, it is not relevant.
After a year of experiments and optimizations to improve our targeting on top of AdSense, it became clear that we were not going to be able to bend it to our will. AdSense wants to target by itself. Any attempt to push it in one direction or another seems doomed to failure.
We decided to switch to a system where we would have more control. When we advertise books, Findory is completely responsible for the targeting. We analyze the Findory page and a reader's history, then our ad system picks specific books at Amazon based on that data.
Going back to that "Google" keyword test case, if I tell Findory's new advertising engine to target to the keyword "Google" (and nothing else), Findory responds with ads for four books: "The AdSense Code", "The Google Story", O'Reilly's "Google Advertising Tools", and "Google Maps Hacks". Ah, much better.
The new book ads target to any page on Findory in real-time as the content changes. Check out the targeting for Wired Magazine, ScienceDaily, Gizmodo, and Google Blogoscoped. And, of course, don't miss the targeting on your personalized Findory front page and how the ads change as you click on new articles.
The performance of the new ad system is roughly the same as the old Google AdSense system. Clickthroughs are much higher than what they were before but, because Amazon Associates has a much lower effective payment per click (about $.05), the incoming revenue is a little lower.
I like the new system much better. The ads are relevant and useful. We have complete control. And, I like helping people discover new books.
Update: Four months later, the results of this experiment are not looking as positive as I had hoped. Amazon Associates effective payment per click is closer to $.02 ($20 average price of a book * 6% associates share * 2% clickthrough-to-sale rate = $.024). AdSense generates $.10 or more per click, so our targeting of Amazon books would have to be x5 more effective or better just to make up for the difference in compensation, probably more like x10 to really be worthwhile. x5-10 improvement in targeting is a high bar, and we have not been able to get anywhere close to that yet.
Update: Eight months later, Findory switches back to Google ads. Unfortunately, the Amazon ads could not be made competitive given the effective payment per click.
Like the old engine, the new engine targets based on the content of the page and each reader's clickstream history on Findory. Unlike the old engine, it shows a targeted selection of books from Amazon rather than text ads from Google AdSense.
Why did Findory switch?
AdSense is an intelligent, self-optimizing, ad targeting system. It is a stubborn beast, convinced it knows what is right.
When Findory layered its own intelligent ad targeting system on top of AdSense, the two fought like crazed monkeys.
Findory would tell AdSense, "This page has articles about Google, Yahoo, search, engines, and technology," and then ask Google to target ads. Given that description, what do you think would be reasonable? Probably ads for web search engines and things related to web search engines?
Instead, Google sometimes would respond with ads for aircraft or automobile engines, blindly fixating on the word "engine" and apparently ignoring the rest of the information. It is hard to work with that.
We even tried test cases where we sent them nothing but a single keyword. For example, we said, "This page is about 'Google'." AdSense sometimes responded with ads for get-rich-quick schemes and penny stocks. That may be amusingly ironic. It even may be lucrative. But, it is not relevant.
After a year of experiments and optimizations to improve our targeting on top of AdSense, it became clear that we were not going to be able to bend it to our will. AdSense wants to target by itself. Any attempt to push it in one direction or another seems doomed to failure.
We decided to switch to a system where we would have more control. When we advertise books, Findory is completely responsible for the targeting. We analyze the Findory page and a reader's history, then our ad system picks specific books at Amazon based on that data.
Going back to that "Google" keyword test case, if I tell Findory's new advertising engine to target to the keyword "Google" (and nothing else), Findory responds with ads for four books: "The AdSense Code", "The Google Story", O'Reilly's "Google Advertising Tools", and "Google Maps Hacks". Ah, much better.
The new book ads target to any page on Findory in real-time as the content changes. Check out the targeting for Wired Magazine, ScienceDaily, Gizmodo, and Google Blogoscoped. And, of course, don't miss the targeting on your personalized Findory front page and how the ads change as you click on new articles.
The performance of the new ad system is roughly the same as the old Google AdSense system. Clickthroughs are much higher than what they were before but, because Amazon Associates has a much lower effective payment per click (about $.05), the incoming revenue is a little lower.
I like the new system much better. The ads are relevant and useful. We have complete control. And, I like helping people discover new books.
Update: Four months later, the results of this experiment are not looking as positive as I had hoped. Amazon Associates effective payment per click is closer to $.02 ($20 average price of a book * 6% associates share * 2% clickthrough-to-sale rate = $.024). AdSense generates $.10 or more per click, so our targeting of Amazon books would have to be x5 more effective or better just to make up for the difference in compensation, probably more like x10 to really be worthwhile. x5-10 improvement in targeting is a high bar, and we have not been able to get anywhere close to that yet.
Update: Eight months later, Findory switches back to Google ads. Unfortunately, the Amazon ads could not be made competitive given the effective payment per click.
Friday, September 22, 2006
R.I.P. Froogle?
Google apparently has decided to retire its metashopping search, Froogle. From an article by Ben Charny at Marketwatch:
There are several other comparison shopping sites available, including Shopzilla, Shopping.com, PriceGrabber, Smarter.com, and mySimon.
[Found via Paul Kedrosky]
Update: John Battelle pings Google PR and gets the response that "Froogle is alive and well." This may be a denial that Froogle is going to be shut down, but it also could be semantic games with the present versus future tense. Hard to tell.
Google intends to "de-emphasize" its own Froogle shopping search engine, a Web site featuring paid listings from eBay and other online retailers. Google intends for Froogle to no longer be a standalone Web site; instead its listings would be absorbed by other search features, [analyst Robert] Peck wrote.That is sad. I have always liked Froogle and had high hopes for it ([1] [2] [3] [4]), but it has been woefully lacking in attention in the last year or two. Even so, I am surprised Google is deciding to shut Froogle down rather than improve it.
There are several other comparison shopping sites available, including Shopzilla, Shopping.com, PriceGrabber, Smarter.com, and mySimon.
[Found via Paul Kedrosky]
Update: John Battelle pings Google PR and gets the response that "Froogle is alive and well." This may be a denial that Froogle is going to be shut down, but it also could be semantic games with the present versus future tense. Hard to tell.
Winner takes all, relevancy, and personalized search
Eric Goldman has an interesting article in InformIT that talks about personalization and its coming impact on search. Some excerpts:
Currently, search engines principally use "one size fits all" ranking algorithms to deliver homogeneous search results to searchers with heterogeneous search objectives.See also my March 2005 post, "The key challenge is personalization", where I said:
Personalized algorithms produce search results that are custom-tailored to each searcher's interests, so different searchers will see different results.
Personalized ranking algorithms represent the next major advance in search relevancy ... Improvements in one-size-fits-all algorithms will yield progressively smaller relevancy benefits. Personalized algorithms transcend those limits [by] optimizing relevancy for each searcher.
Personalized ranking algorithms also reduce the effects of search engine bias. Personalized algorithms mean that there are multiple "top" search results for a particular search term, instead of a single "winner," so web publishers won't compete against each other in a zero-sum game ... Also, personalized algorithms necessarily will diminish the weight given to popularity-based metrics (to give more weight for searcher-specific factors), reducing the structural biases due to popularity.
With only one generalized relevance rank, further improvements to search quality become increasingly difficult because people disagree on how relevant a particular page is to a particular search.See also my July 2006 post, "Combating web spam with personalization", where I said:
At some point, to get further improvements, relevance rank will have to be customized to each person's definition of relevance.
Another way to reduce the value [of web spam] is to reduce the maximum payoff. If different people see different search results, spamming becomes much less attractive. The jackpot from getting to the top of the page disappears.See also my August 2006 post, "Web spam, AIRWeb, and SIGIR", where I said:
Personalized search shows different search results to different people based on their history and their interests. Not only does this increase the relevance of the search results, but also it makes the search results harder to spam.
"Winner takes all" encourages spam. When spam succeeds in getting the top slot, everyone sees the spam. It is like winning the jackpot.
If different people saw different search results -- perhaps using personalization based on history to generate individualized relevance ranks -- this winner takes all effect should fade and the incentive to spam decline.
Social networks and phishing
This "Social Phishing" paper (PDF) that will appear in an upcoming issue of Communications of the ACM is frightening. It describes very successful phishing attacks using information pulled off social networking sites.
From the paper:
The paper contains other interesting details such as differences in success rates according to field of study and gender of sender and receiver.
See also a Google Tech Talk on Google Video, "Badvertisements: Stealthy Click Fraud with Unwitting Accessories", by Markus Jakobsson, one of the authors of the paper, that discusses this phishing study and some of his other work on click fraud.
Update: If you liked this, don't miss Markus' demonstration of a crafty CSS/Javascript hack that reveals parts of your browser history. To see it, click on the "View" link on the right side of his page.
From the paper:
The question we ask here is how easily and how effectively a phisher can exploit social network data found on the Internet to increase the yield of a phishing attack. The answer, as it turns out, is: very easily and very effectively.When they received the e-mail to go to this non-University website, 349 of the 487 students targeted provided their University username and password. Remarkable and frightening.
Our study suggests that Internet users may be over four times as likely to become victims if they are solicited by someone appearing to be a known acquaintance.
To mine information about relationships and common interests in a group or community, a phisher need only look at any one of a growing number of social network sites, such as Friendster (friendster.com), MySpace (myspace.com), Facebook (facebook.com), Orkut (orkut.com), and LinkedIn (linkedin.com). All these sites identify "circles of friends" which allow a phisher to harvest large amounts of reliable social network information.
The experiment spoofed an email message between two friends, whom we will refer to as Alice and Bob. The recipient, Bob, was redirected to a phishing site with a domain name clearly distinct from Indiana University; this site prompted him to enter his secure University credentials. In a control group, subjects received the same message from an unknown fictitious person with a University email address.
The 4.5-fold difference between the social network group and the control group is noteworthy. The social network group's success rate (72%) was much higher than we had anticipated.
The paper contains other interesting details such as differences in success rates according to field of study and gender of sender and receiver.
See also a Google Tech Talk on Google Video, "Badvertisements: Stealthy Click Fraud with Unwitting Accessories", by Markus Jakobsson, one of the authors of the paper, that discusses this phishing study and some of his other work on click fraud.
Update: If you liked this, don't miss Markus' demonstration of a crafty CSS/Javascript hack that reveals parts of your browser history. To see it, click on the "View" link on the right side of his page.
Thursday, September 21, 2006
Boxwood from Microsoft Research
If you enjoyed the Google Bigtable, Chubby, and GFS papers, you might also enjoy a recent paper out of Microsoft Research, "Boxwood: Abstractions as the Foundation for Storage Infrastructure".
The basic idea is to create a distributed data store over a small cluster. It is similar in motivation to Bigtable and GFS, but lower-level. From the paper:
It is also worth noting that they have different standards for failure tolerance. For one of several examples, the Boxwood paper says that "failures are assumed to be fail-stop". Contrast that with the experience of the folks at Google working on Bigtable:
See also my previous post, "Yahoo building a Google FS clone?", that talks about Yahoo's involvement in Hadoop.
See also the Eclipse project at Microsoft Research.
Update: Mary Jo Foley mentions another Microsoft Research project called Dryad and quotes Bill Gates as saying, "[Google] did MapReduce; we have this thing called Dryad that's better." Unfortunately, there appears to be very little public information on Dryad; I can find no publications on the work.
Update: A year later, Microsoft Researcher Michael Isard gives a Google Tech Talk on Dryad with plenty of details.
The basic idea is to create a distributed data store over a small cluster. It is similar in motivation to Bigtable and GFS, but lower-level. From the paper:
The overall goal of the Boxwood project is to experiment with data abstractions as the underlying basis for storage infrastructure ... [that includes] redundancy and backup schemes to tolerate failures, expansion mechanisms for load and capacity balancing, and consistency maintenance in the presence of failures.It is worth noting right away that Boxwood is a research project, not a deployed system. The Boxwood prototype runs on a small cluster of eight machines. GFS and Bigtable run on tens of thousands of machines and provide the backend for many of Google's products.
The principal client-visible abstractions that Boxwood provides are a B-tree abstraction and a simple chunk store abstraction provided by the Chunk Manager.
It is also worth noting that they have different standards for failure tolerance. For one of several examples, the Boxwood paper says that "failures are assumed to be fail-stop". Contrast that with the experience of the folks at Google working on Bigtable:
One lesson we learned is that large distributed systems are vulnerable to many types of failures, not just the standard network partitions and fail-stop failures assumed in many distributed protocols.In any case, the Boxwood paper is an interesting read. This is work at Microsoft that may follow a similar path to GFS and Bigtable.
For example, we have seen problems due to all of the following causes: memory and network corruption, large clock skew, hung machines, extended and asymmetric network partitions, bugs in other systems that we are using (Chubby for example), overflow of GFS quotas, and planned and unplanned hardware maintenance.
See also my previous post, "Yahoo building a Google FS clone?", that talks about Yahoo's involvement in Hadoop.
See also the Eclipse project at Microsoft Research.
Update: Mary Jo Foley mentions another Microsoft Research project called Dryad and quotes Bill Gates as saying, "[Google] did MapReduce; we have this thing called Dryad that's better." Unfortunately, there appears to be very little public information on Dryad; I can find no publications on the work.
Update: A year later, Microsoft Researcher Michael Isard gives a Google Tech Talk on Dryad with plenty of details.
Wednesday, September 20, 2006
The Daily You paper
Lawrence Kai Shih and David Karger at MIT wrote an interesting WWW2004 paper, "Using URLs and Table Layout for Web Classification Tasks", about a news recommender system they called "The Daily You".
The recommender system is unusual in that it uses proximity on a page and similarities in the URLs to find related articles. From the paper:
The recommender system is unusual in that it uses proximity on a page and similarities in the URLs to find related articles. From the paper:
In recommendation systems ... typically, the Web is treated as a large text corpus: the numerous features used are the words in the documents, and standard machine learning algorithms such as Naive Bayes or support vector machines are applied.Shih and Karger are saying that human editors already identify related articles by putting them in close proximity, either close together on a web page or by giving them similar URLs on their website. They try to extract and exploit that to generate good news recommendations. It is a cute idea.
The Web is more than just text, however: it contains rich, human-oriented structure suitable for learning. In this paper, we argue that two features particular to Web documents, URLs and the visual placement of links on a page, can be of great value in document classification. We show that machine-learning classifiers based on these features can be simultaneously more efficient and more accurate than those based on the document text.
Our motivating example for these classification problems is The Daily You, a tool providing personalized news recommendations from the Web. The Daily You uses URLs and table layout to solve two important classification problems: the blocking of Web advertisements and the page regions and outbound hyper-links predicted to be "interesting" to its user.
Tuesday, September 19, 2006
Tagging should be automated
Yahoo PM Matt McAlister posts some thoughts on the mainstream and the effort involved with tagging. Some excerpts:
See also my previous posts, "Manual vs. automated tagging" and "Social software is too much work".
My mother will never organize her web pages with tags.See also today's post on the Dead 2.0 blog, "Ask Skeptic's Mom: What's Tagging?"
What's missing from the tagging world is automatic learning. People shouldn't have to find the 'save' button, click it, fill in tags, and hit save. My browser history says a lot about what interests me. The time I spend on a page says a lot about what I value. Any social activities I initiate or receive can inform a machine what the world around me thinks about.
The influencer is clearly willing to work harder ... but everyone else will need something more personal to happen as a result of tagging to warrant the amount of effort to do it.
See also my previous posts, "Manual vs. automated tagging" and "Social software is too much work".
Trying to improve search user interfaces
Danny Sullivan has a good post, "Why Search Sucks & You Won't Fix It The Way You Think", that looks at the lack of innovation in search user interfaces and several failed attempts to improve them.
Danny does not get into details about why the attempts at improvements did not succeed, but I think it comes down to too much work.
Type stuff in a box, punch a button. That's easy and it works most of the time.
To be an improvement, any substantial change in that UI paradigm will have to be clearly easier to use or produce substantially better results almost all the time. Probably both. That's a high bar.
Type stuff, push a button. It's going to be hard to beat.
Danny does not get into details about why the attempts at improvements did not succeed, but I think it comes down to too much work.
Type stuff in a box, punch a button. That's easy and it works most of the time.
To be an improvement, any substantial change in that UI paradigm will have to be clearly easier to use or produce substantially better results almost all the time. Probably both. That's a high bar.
Type stuff, push a button. It's going to be hard to beat.
Is Soapbox Live or MSN?
Microsoft recently launched a YouTube-clone called MSN Soapbox.
Pretty much everything I thought about saying about this has already been said by Mike and Carlo at TechDirt in their excellent two ([1] [2]) posts.
But, I think Matt Marshall nailed another issue when he said, "Why this is being released under the MSN brand is beyond us. Microsoft's branding, between Live and MSN, is getting confusing."
See also my previous posts, "Is it Windows Live, MSN, or Microsoft?" and "Is it Live or MSN?"
Pretty much everything I thought about saying about this has already been said by Mike and Carlo at TechDirt in their excellent two ([1] [2]) posts.
But, I think Matt Marshall nailed another issue when he said, "Why this is being released under the MSN brand is beyond us. Microsoft's branding, between Live and MSN, is getting confusing."
See also my previous posts, "Is it Windows Live, MSN, or Microsoft?" and "Is it Live or MSN?"
Chubby: The Google distributed lock manager
Google has released a new OSDI 2006 paper, "The Chubby Lock Service for Loosely-Coupled Distributed Systems".
From the paper:
The paper talks about many of the practical issues they encountered building this large-scale system. It is a good read.
There is one rather silly thing I cannot resist commenting on. I thought the somewhat negative tone the paper takes toward Google developers was amusing. For example, the paper says at various points:
On the other hand, I think developers just want to create a reliable distributed lock for their applications and don't care how it is done. They want the process to be transparent. Give me a friggin' lock already.
From the tone of these criticisms, I suspect Chubby is not doing enough to make that happen for Google developers. I would not be surprised if there were other competing distributed lock systems at Google created by people who find Chubby does not quite meet their needs.
But, in the end, these are the problems any company with many developers working on complex distributed systems will encounter. It is not surprising the geniuses at Google hit them too. But, I have to say, I did find the tone in this paper toward Google developers a little amusing.
See also my previous post, "Google Bigtable paper".
[Found via Dan Creswell]
From the paper:
Chubby is a distributed lock service intended for coarse-grained synchronization of activities within Google's distributed systems.Chubby is a relatively heavy-weight system intended for coarse-grained locks, locks held for "hours or days", not "seconds or less."
Chubby has become Google's primary internal name service; it is a common rendezvous mechanism for systems such as MapReduce; the storage systems GFS and Bigtable use Chubby to elect a primary from redundant replicas; and it is a standard repository for files that require high availability, such as access control lists.
The paper talks about many of the practical issues they encountered building this large-scale system. It is a good read.
There is one rather silly thing I cannot resist commenting on. I thought the somewhat negative tone the paper takes toward Google developers was amusing. For example, the paper says at various points:
Our developers sometimes do not plan for high availability in the way one would wish. Often their systems start as prototypes with little load and loose availability guarantees; invariably the code has not been specially structured for use with a consensus protocol. As the service matures and gains clients, availability becomes more important; replication and primary election are then added to an existing design.Well, okay, on the one hand, I am sympathetic with the designers of Chubby when they say that all developers working on at Google need to be aware of the complex reliability issues in distributed systems.
Developers are often unable to predict how their services will be used in the future, and how use will grow.
A module written by one team may be reused a year later by another team with disastrous results ... Other developers may be less aware of the cost of an RPC.
Our developers are confused by non-intuitive caching semantics.
Despite attempts at education, our developers regularly write loops that retry indefinitely when a file is not present, or poll a file by opening it and closing it repeatedly when one might expect they would open the file just once.
Developers rarely consider availability. We find that our developers rarely think about failure probabilities.
Developers also fail to appreciate the difference between a service being up, and that service being available to their applications.
Unfortunately, many developers chose to crash their applications on receiving [a failover] event, thus decreasing the availability of their systems substantially.
On the other hand, I think developers just want to create a reliable distributed lock for their applications and don't care how it is done. They want the process to be transparent. Give me a friggin' lock already.
From the tone of these criticisms, I suspect Chubby is not doing enough to make that happen for Google developers. I would not be surprised if there were other competing distributed lock systems at Google created by people who find Chubby does not quite meet their needs.
But, in the end, these are the problems any company with many developers working on complex distributed systems will encounter. It is not surprising the geniuses at Google hit them too. But, I have to say, I did find the tone in this paper toward Google developers a little amusing.
See also my previous post, "Google Bigtable paper".
[Found via Dan Creswell]
Diagnosing failures in Amazon's systems
Robin Harris points out a paper, "Advanced Tools for Operators at Amazon.com" (PDF), that talks about tracking and diagnosing failures in Amazon.com's distributed backend of web services.
The paper describes some of the complexity of this task:
In the comments, I asked, "Why do web services necessarily eliminate dependencies? Can you not have the same complicated nest of dependencies in a cloud of web services, all of them talking to each other in an incomprehensible chatter?"
I do worry that Amazon may have taken a complex web of dependencies in libraries and moved that to a complex web of dependencies in web services. Since web service calls look like heavyweight library calls to developers, it is not clear to me that web services necessarily reduce dependencies, not without a special effort to make sure they do.
Moreover, as this paper describes, there is additional complexity in a distributed system of web services, in particular the difficulty of debugging and profiling across remote calls.
I noticed the authors of this paper include the widely respected Professor Michael Jordan at UC Berkeley in addition to several people at Amazon.com. Very interesting.
It is unusual to see Amazon publish academic papers on their work. Historically, they have not been as open as Google or Microsoft Research. I am excited to see more papers coming out of Amazon describing the challenging problems they are solving internally.
[Robin Harris post found via Dan Creswell]
The paper describes some of the complexity of this task:
Complex dependencies among system components can cause failures to propagate to other components, triggering multiple alarms and complicating root-cause determination.This reminds me of a post by Werner Vogels a few months ago. Talking about Amazon's rearchitecture efforts, Werner had said, "A service-oriented architecture would give us the level of isolation that would allow us to build many software components rapidly and independently."
Maya is a new visualization tool ... [that] displays the dependencies among components as a directed graph. Each component -- web page, service, or database -- is represented as a black (healthy) or red (unhealthy) dot.
The operators thus clearly see which components that are reporting alarms may simply be suffering from a cascaded failure.
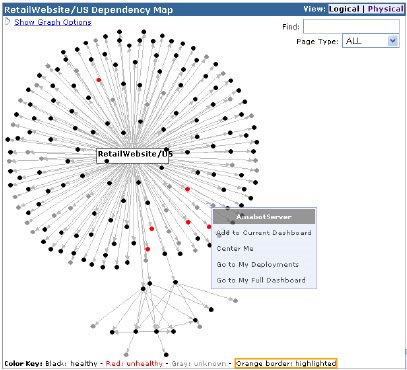
In the comments, I asked, "Why do web services necessarily eliminate dependencies? Can you not have the same complicated nest of dependencies in a cloud of web services, all of them talking to each other in an incomprehensible chatter?"
I do worry that Amazon may have taken a complex web of dependencies in libraries and moved that to a complex web of dependencies in web services. Since web service calls look like heavyweight library calls to developers, it is not clear to me that web services necessarily reduce dependencies, not without a special effort to make sure they do.
Moreover, as this paper describes, there is additional complexity in a distributed system of web services, in particular the difficulty of debugging and profiling across remote calls.
I noticed the authors of this paper include the widely respected Professor Michael Jordan at UC Berkeley in addition to several people at Amazon.com. Very interesting.
It is unusual to see Amazon publish academic papers on their work. Historically, they have not been as open as Google or Microsoft Research. I am excited to see more papers coming out of Amazon describing the challenging problems they are solving internally.
[Robin Harris post found via Dan Creswell]
Monday, September 18, 2006
The problem with YouTube
Mark Cuban nails it in his post, "The Coming Dramatic Decline of Youtube":
But, I don't think ease of use is the reason most people use YouTube. I suspect most people go to YouTube to view copyright content. Nothing attracts an audience like giving away something that normally costs money for free.
Like Napster, YouTube probably owes much of its success to playing fast and loose with copyright law. Like Napster, they likely will find that it is not sustainable.
[Found via John Battelle]
Update: A nice follow-up post on this by Don Dodge.
Update: Another good post from Mark Cuban on YouTube. [via Don Dodge]
The fact that Youtube is building a traffic juggernaut around copyrighted audio and video without being sued is like.... well Napster at the beginning as the labels were trying to figure out what it meant to them. ... It's just a question of when Youtube will be hit with a charge of inducing millions of people to break copyright laws, not if.I like YouTube, don't get me wrong. I think they did a great job making it easy to upload and view videos on the Web.
Take away all the copyrighted material and you take away most of Youtube's traffic. Youtube turns into a hosting company with a limited video portal. Like any number of competitors out there that decided to follow copyright law.
But, I don't think ease of use is the reason most people use YouTube. I suspect most people go to YouTube to view copyright content. Nothing attracts an audience like giving away something that normally costs money for free.
Like Napster, YouTube probably owes much of its success to playing fast and loose with copyright law. Like Napster, they likely will find that it is not sustainable.
[Found via John Battelle]
Update: A nice follow-up post on this by Don Dodge.
Update: Another good post from Mark Cuban on YouTube. [via Don Dodge]
Thursday, September 14, 2006
Building Google Calendar
Rakesh Agrawal posts detailed notes on a talk by Google PM Carl Sjogreen on how Google built Google Calendar.
My favorite tidbits mostly were in the lessons learned at the end:
[Found via Philipp Lenssen]
My favorite tidbits mostly were in the lessons learned at the end:
Easy is the most important feature.Well worth reading.
Always have an eye on the minimum useful feature set that most people will use.
Go talk to "real" customers .... Talk to grandma.
Focus on what the web can do that paper can't: collaboration, access from anywhere.
[Found via Philipp Lenssen]
The bubble is back
In a move that cannot help but bring up memories of Pets.com, Dogster just got $1M in funding.
Tuesday, September 12, 2006
1000th post on Geeking with Greg
This is the 1000th post on Geeking with Greg. 2 1/2 years of posting, roughly 200k words in total, averaging a little more than a post a day. Whew!
Over that time, traffic to this weblog has grown. There are 1,120 subscribers in Bloglines now. Apparently, a good rule of thumb is to multiply that by x4 to get the total number of regular readers, so this means a few thousand people are regularly reading this little weblog.
According to Google Analytics, this weblog gets about 30k page views per month (and, before you ask, yes, that is much lower than the traffic to Findory, more than two orders of magnitude lower).
In 2006, the most popular posts on Geeking with Greg were:
While the point of this weblog is to talk about personalized information, some posts departed from this theme. In particular, I much enjoyed the Early Amazon series about my first couple years at Amazon.com.
Thanks to everyone who reads this weblog. I hope you have enjoyed it as much as I have.
Over that time, traffic to this weblog has grown. There are 1,120 subscribers in Bloglines now. Apparently, a good rule of thumb is to multiply that by x4 to get the total number of regular readers, so this means a few thousand people are regularly reading this little weblog.
According to Google Analytics, this weblog gets about 30k page views per month (and, before you ask, yes, that is much lower than the traffic to Findory, more than two orders of magnitude lower).
In 2006, the most popular posts on Geeking with Greg were:
- "In a world with infinite storage, bandwidth, and CPU power", a post that covered some information accidentally leaked by Google in some slides.
- "A chance to play with big data" about AOL Research's release of query log data.
- "Google's BigTable" about the massive, distributed, custom database behind many of Google's products.
- "Kill Google, Vol. 3", a post about attacking AdSense to beat Google rather than going after search.
- "Personalized search at PC Forum"
- "Google Personalized Search and Bigtable"
- "More on Google personalized search"
- "The value of recommendations"
- "Organizing chaos and information overload"
- "Zen and the art of Amazon recommendations"
- "New personalized web search at Findory"
- "Standing interests, search, and recommendations"
- "Personalized search vs. clustering"
- "Is personalized search a dead end?"
- "Personalized search paper from MSR"
- "Is personalized advertising evil?"
- "Personalized blog search"
- "Personalized TV advertising"
- "BitTorrent, Internet TV, and personalization"
- "John Doerr on personalized information"
- "Why personalized news?"
- "Beyond the commons: Personalized web search"
- "Search as a dialog and personalized search"
- "Andrei Broder on personalized information"
- "What is personalization?"
- "Combating web spam with personalization"
- "Yahoo home page cries out for personalization"
- "Personalization is hard. So what?"
- "Personalization and the long tail"
- "Personalization should not require effort"
- "Social networks vs. personalization"
- "Perfect Search and the clickstream"
- "Personalized search RSS feeds"
- "Recommender systems and toy problems"
While the point of this weblog is to talk about personalized information, some posts departed from this theme. In particular, I much enjoyed the Early Amazon series about my first couple years at Amazon.com.
Thanks to everyone who reads this weblog. I hope you have enjoyed it as much as I have.
Microsoft Live.com and the search war
It is being widely reported that Microsoft is launching a new version of Live.com, the revised version of the MSN search engine and portal, and redirecting more of MSN traffic to Live.com.
Todd Bishop at the Seattle PI has one of the best write-ups I have seen so far. Some excerpts:
However, Microsoft has their control of the desktop to leverage. In particular, they have the default home page and search (MSN/Live.com) on the default browser (IE) on the default operating system (Windows). They also have control of the dominant office suite (MS Office) and mail clients (MS Outlook & MS Outlook Express).
It is a damning indictment of MSN that such a remarkable number of people go through the effort of switching those defaults to Google or Yahoo when they get a new computer.
As people buy new computers, if Live.com can get to a level where it is perceived as "good enough", more people may lazily stick with the Microsoft default. Because of their control of the desktop, good enough may be good enough for Microsoft.
See also my October 2005 post, "Don Dodge on Altavista and the search war".
Todd Bishop at the Seattle PI has one of the best write-ups I have seen so far. Some excerpts:
"Google is so synonymous with Web search," said analyst Greg Sterling of Sterling Market Intelligence ... "You really have to offer something that's quite different and seemingly better to get people off of their habitual behavior."I think both of these points are correct. Google is synonymous with search, so Live.com has to be either substantially better or well differentiated to get people actively to switch.
One way the company may gain ground is by creating links to Windows Live Search from its various products and online services, analysts said. But rivals and antitrust regulators also want to make sure Microsoft doesn't use the dominant position of its Windows operating system and Internet Explorer to unfairly advantage its search engine.
However, Microsoft has their control of the desktop to leverage. In particular, they have the default home page and search (MSN/Live.com) on the default browser (IE) on the default operating system (Windows). They also have control of the dominant office suite (MS Office) and mail clients (MS Outlook & MS Outlook Express).
It is a damning indictment of MSN that such a remarkable number of people go through the effort of switching those defaults to Google or Yahoo when they get a new computer.
As people buy new computers, if Live.com can get to a level where it is perceived as "good enough", more people may lazily stick with the Microsoft default. Because of their control of the desktop, good enough may be good enough for Microsoft.
See also my October 2005 post, "Don Dodge on Altavista and the search war".
Monday, September 11, 2006
Making humanity more intelligent
In "Artificial Intelligentsia" (subscription required) in this month's Atlantic Monthly, James Fallows has a nice passage on the goals of those working on the future of search:
Idealistic, yes, but it is what motivates me and, I think, many others.
On a side note, I have a brief quote deep in this article giving a simplified explanation of recommender systems:
These new tools could ... become the modern-day equivalent of the steam engine or the plow -- tools that free people from routine chores and give them more time to think, dream, and live. Each previous wave of invention has made humanity more intelligent overall.Improving our access to knowledge makes us smarter. Information is power, and the more who have information, the more powerful humanity will become.
The next wave of tech innovation, if it is like all the previous ones, will again make us smarter. If we take advantage of its effects, it might even make us wiser, too.
Idealistic, yes, but it is what motivates me and, I think, many others.
On a side note, I have a brief quote deep in this article giving a simplified explanation of recommender systems:
"A way to look at these social filtering systems is to think of them as generating millions of 'most popular' lists, and finding the most-popular items for people like you," Greg Linden, who designed Amazon's recommendations system, told me in an e-mail.This is not strictly true, by the way. Everyone buys Harry Potter, so a bestseller list for people like me is likely to be dominated by Harry Potter. What you really want is something closer to "unusually popular with people like me."
"Normal best-seller lists are uninteresting to me because my tastes are not generic. But a best-selling list for people who buy some of the same books I do -- that is likely to be interesting."
Google recommendation widget
Ionut Alex Chitu notes that Google now has a recommendation module for their personalized home page.
The module is called "Interesting Items For You" and recommends three things: "recent top queries related to your searches", "web pages related to your searches", and other gadgets for your personalized home page.
In my usage, the queries appeared to be mostly based on my geolocation, not on my search history. The top three recommended queries were "evergreen state fair", "seatac airport", and "seahawks", not particularly relevant or useful to me, but apparently targeted to my Seattle location. The recommended gadget was the Seattle PI module. The recommended web pages also had a Seattle focus, but near the bottom also included links to KDD 2006 and IJCAI 2007 (probably based on a lot of hits to SIGIR in my search history).
It is an interesting experiment. However, I think it suffers from the same problem as Google Personalized Search, focusing too much on a high-level, coarse-grained profile based on long-term behavior. I suspect the gadget would be more useful if it focused on your recent behavior -- what you are doing now -- and adapted rapidly to shifts in your current interests.
See also my earlier post, "Google Personalized Search and Bigtable".
[Found via Phil Bradley]
Update: Niall Kennedy posts a nice review and includes a brief description of the API to access the recommendations.
Update: A friend, also in Seattle, sent me his recommended searches. The top four were identical to mine. This would seem to support the claim that the recommendations are too coarse-gained and based too much on location.
Update: The recommendations do not change as I execute new searches or click on new items. They do not adapt to new data.
Update: About two days and a hundred searches later, the recommendations still have not changed. Wow, these are really static. That's no good at all.
The module is called "Interesting Items For You" and recommends three things: "recent top queries related to your searches", "web pages related to your searches", and other gadgets for your personalized home page.
In my usage, the queries appeared to be mostly based on my geolocation, not on my search history. The top three recommended queries were "evergreen state fair", "seatac airport", and "seahawks", not particularly relevant or useful to me, but apparently targeted to my Seattle location. The recommended gadget was the Seattle PI module. The recommended web pages also had a Seattle focus, but near the bottom also included links to KDD 2006 and IJCAI 2007 (probably based on a lot of hits to SIGIR in my search history).
It is an interesting experiment. However, I think it suffers from the same problem as Google Personalized Search, focusing too much on a high-level, coarse-grained profile based on long-term behavior. I suspect the gadget would be more useful if it focused on your recent behavior -- what you are doing now -- and adapted rapidly to shifts in your current interests.
See also my earlier post, "Google Personalized Search and Bigtable".
[Found via Phil Bradley]
Update: Niall Kennedy posts a nice review and includes a brief description of the API to access the recommendations.
Update: A friend, also in Seattle, sent me his recommended searches. The top four were identical to mine. This would seem to support the claim that the recommendations are too coarse-gained and based too much on location.
Update: The recommendations do not change as I execute new searches or click on new items. They do not adapt to new data.
Update: About two days and a hundred searches later, the recommendations still have not changed. Wow, these are really static. That's no good at all.
Sunday, September 10, 2006
The problem with forced rank
Kelley Holland at the NYT writes an article called "Performance Reviews: Many Need Improvement" about problems with forced rank.
From the article:
Here, it is worth considering the results of a study described in Worth Magazine (PDF) on the relationship between morale and company performance:
Back on problems with forced rank, I enjoyed this tidbit at the end of the NYT article:
See also my May 2006 post, "Microsoft drops forced rank, increases perks".
See also my April 2004 post, "The Human Equation".
From the article:
Under this system ... managers sort fixed percentages of their employees into categories like "superior" or "needing improvement"; those in the top group typically receive the best compensation, training and promotions while those at the bottom may be denied raises or promotions, or even fired.On this last point, I suspect that the initial gain is because the forced rank is used at first to fire employees who should have been nudged out of the company a long time ago. After that first win, further gains are lost to damage to morale and team cohesion.
Critics ... contended that rating -- and even firing -- employees by using a statistical curve hurt morale and teamwork, and that vague standards opened the door to bias.
Empirical evidence is mixed on the effectiveness of forced rankings. A study last year ... found that if a company used the ranking system and fired 10 percent of lower-ranked employees, that company's performance improved markedly, but the gains shrank rapidly in successive years.
Here, it is worth considering the results of a study described in Worth Magazine (PDF) on the relationship between morale and company performance:
Our research shows repeatedly that the relationship between morale and performance is reciprocal -- a "virtuous circle."I think the "gift" point is particularly important. Treating people well can be seen as a form of gift exchange, creating more of a friendship than purely economic relationship between the company and the employees. Put simply, people care more about a company that cares about them.
In both 2004 and 2005, the stock prices of companies with high morale ... outperformed similar companies in their same industries by a ratio of 2.5 to 1. Meanwhile, the stock prices of companies with medium or low morale lagged behind their industry peers by greater than 1.5 to 1.
Why is high employee morale so strongly related to stock prices? Morale is a direct consequence of being treated well by a company, and employees return the "gift" of good treatment with higher productivity.
There are three factors that fuel employee enthusiasm: fair treatment, such as equitable wages and benefits ... a sense of achievement or pride ... and camaraderie among co-workers.
Back on problems with forced rank, I enjoyed this tidbit at the end of the NYT article:
Critics of performance reviews have been around for a very, very long time. When the Wei dynasty in China rated the performance of its household members in the third century A.D., the philosopher Sin Yu noted that "an imperial rater of nine grades seldom rates men according to their merits, but always according to his likes and dislikes."Ah, yes, wouldn't it be wonderful if modern management could learn lessons that were apparent 1750 years ago?
See also my May 2006 post, "Microsoft drops forced rank, increases perks".
See also my April 2004 post, "The Human Equation".
Saturday, September 09, 2006
Talk on the future of networking
Van Jacobson (Research Fellow at PARC, former Chief Scientist at Cisco Systems) gave a nice, high-level, visionary Google Tech Talk called "A New Way to look at Networking".
He says that networking needs to move from focusing on a connection between two computers to focusing on movements of data. He refers to this new type of network as a dissemination-based network.
In this vision, the network is optimized to retrieve named chunks of data from any available resource nearby over any available communication channel (e.g. "Someone, send me X."). This is in contrast with current networks that emphasize setting up a connection between two specific machines over a specific communication channel (e.g. "Connect to machine A.B.C.D.").
Van mentions BitTorrent and other examples as early but ad hoc progress toward this type of network structure. He criticized weaknesses in these early systems, saying, for example, that BitTorrent only worked well for very large files.
Far be it for me to disagree with Van about anything related to networking, but I have to admit this is where I started to question the proposal.
It seems to me it is exactly large data -- big, mostly unchanging video and audio files -- that is amenable to a data sharing infrastructure like Van is proposing. I would think that e-mails, dynamic web pages, and other types of rapidly changing, more personal data would get little benefit from the dissemination-based network proposed.
But, I may be thinking too small. This is not merely a way to share files.
I could imagine a world where every machine was part of a global mesh, data chunks encrypted and replicated across the cloud when the data is born, individual machines joining and dropping out on a millisecond basis, data migrating on demand and fading when no longer needed. This seems to be closer to the vision laid out in this talk.
It is a fun and worthwhile talk. If you watch it and have comments on it or what I said above, I would enjoy hearing your thoughts.
He says that networking needs to move from focusing on a connection between two computers to focusing on movements of data. He refers to this new type of network as a dissemination-based network.
In this vision, the network is optimized to retrieve named chunks of data from any available resource nearby over any available communication channel (e.g. "Someone, send me X."). This is in contrast with current networks that emphasize setting up a connection between two specific machines over a specific communication channel (e.g. "Connect to machine A.B.C.D.").
Van mentions BitTorrent and other examples as early but ad hoc progress toward this type of network structure. He criticized weaknesses in these early systems, saying, for example, that BitTorrent only worked well for very large files.
Far be it for me to disagree with Van about anything related to networking, but I have to admit this is where I started to question the proposal.
It seems to me it is exactly large data -- big, mostly unchanging video and audio files -- that is amenable to a data sharing infrastructure like Van is proposing. I would think that e-mails, dynamic web pages, and other types of rapidly changing, more personal data would get little benefit from the dissemination-based network proposed.
But, I may be thinking too small. This is not merely a way to share files.
I could imagine a world where every machine was part of a global mesh, data chunks encrypted and replicated across the cloud when the data is born, individual machines joining and dropping out on a millisecond basis, data migrating on demand and fading when no longer needed. This seems to be closer to the vision laid out in this talk.
It is a fun and worthwhile talk. If you watch it and have comments on it or what I said above, I would enjoy hearing your thoughts.
Friday, September 08, 2006
Digg struggles with spam
There have been some interesting posts lately on how Digg is struggling with manipulation and spam.
First, Philipp Lenssen writes about "Digg vs. Groupthink" and the problems of "favoring a submission based on what ... friends favored."
Second, Alex Bosworth posts about "The Prisoner's Dilemma in Digg Story Promotion".
Third, Nick Carr focuses on an "Undiggnified" conflict in the Digg community over new rules intended to reduce manipulation and spam.
These problems with Digg were predictable. Getting to the top of Digg now guarantees a flood of traffic to the featured link. With that kind of reward on the table, people will fight to win placement by any means necessary.
It was not always this way. When Digg was just used by a small group of early adopters, there was little incentive to mess with the system. The gains from bad behavior were low, so everyone played nice.
Now that Digg is starting to attract a large mainstream audience, Digg will be fighting a long and probably losing battle against attempts to manipulate the system for personal gain.
See also my Jan 2006 post, "Digg, spam, and most popular lists".
Update: Pete Abilla also has a good post, "Digg as a game".
Update: Matt Marshall reports that a website called Spike the Vote "lets its members conspire to submit certain URLs of stories -- thereby lifting the odds those stories will get [Digg] front-page coverage."
Update: Niall Kennedy reports that there were "lots of stories about how sites can tap into the Digg's huge audience" at the PubCon Conference. Niall goes on to say that:
For more on that, see my previous posts, "Combating web spam with personalization" and "Web spam, AIRWeb, and SIGIR".
First, Philipp Lenssen writes about "Digg vs. Groupthink" and the problems of "favoring a submission based on what ... friends favored."
Second, Alex Bosworth posts about "The Prisoner's Dilemma in Digg Story Promotion".
Third, Nick Carr focuses on an "Undiggnified" conflict in the Digg community over new rules intended to reduce manipulation and spam.
These problems with Digg were predictable. Getting to the top of Digg now guarantees a flood of traffic to the featured link. With that kind of reward on the table, people will fight to win placement by any means necessary.
It was not always this way. When Digg was just used by a small group of early adopters, there was little incentive to mess with the system. The gains from bad behavior were low, so everyone played nice.
Now that Digg is starting to attract a large mainstream audience, Digg will be fighting a long and probably losing battle against attempts to manipulate the system for personal gain.
See also my Jan 2006 post, "Digg, spam, and most popular lists".
Update: Pete Abilla also has a good post, "Digg as a game".
Update: Matt Marshall reports that a website called Spike the Vote "lets its members conspire to submit certain URLs of stories -- thereby lifting the odds those stories will get [Digg] front-page coverage."
Update: Niall Kennedy reports that there were "lots of stories about how sites can tap into the Digg's huge audience" at the PubCon Conference. Niall goes on to say that:
Some marketers create a story aimed at the Digg audience ... and with the appropriate submitters and human or bot-powered voting rise towards the top. A few search engine marketing consultants are promoting their account status and influence on Digg to clients.Update: Niall Kennedy again writes about spam on Digg with a specific example of how it is done:
There is a lot of activity in the social networking and user generated content space from marketers and spammers.
Last weekend I noticed a Digg submission about weight loss tips had climbed the site's front page, earning a covetous position in the top 5 technology stories of the moment.This is going to be a serious problem for Digg. Because everyone sees the same top stories on Digg -- because it is a simple most popular list -- the incentive to spam it is very high. Digg will be fighting a long and probably losing battle against spammers.
The webmaster of i-dentalresources.com had inserted some Digg bait, seeded a few social bookmarking services, and waited for links and page views to roll in, creating a new node in a spam farm fueled by high-paying affiliate programs and identity collection for resale.
For more on that, see my previous posts, "Combating web spam with personalization" and "Web spam, AIRWeb, and SIGIR".
Thursday, September 07, 2006
Starting Findory: The team
Building a strong team around a startup is important. No doubt about it, I was slow to build a team for Findory.
Findory was started with a very modest amount of capital, probably too small. The on the cheap strategy meant Findory could not pay salaries or benefits. That made hiring and building a team difficult.
I did not want to bring people on part-time who were not dedicated to success of company, but I could not offer what people need -- at least a modest salary -- to come on full time.
In retrospect, I should have increased the initial capital invested, paid small salaries, and brought more people on the team. I was too concerned about the burn rate and not concerned enough about getting the right people on board quickly.
I also should have brought on advisors and formed an advisory board. The assistance and connections would have been valuable. Worries about loss of independence and dilution of ownership should have taken a back seat to getting the advice I needed.
Finally, I should have brought an angel on the team. As I learned with our lawyers, the advice and network I would have gained from a dedicated angel would have been as valuable as the funding. A modest amount of additional funding also would have been sufficient to pay 1/3 salaries to a couple employees, easing the build out of the critical early team.
It is ironic. I started Findory because I was passionate about an idea and loved the speed of execution I gained from my independence. In my excitement, I forgot the importance of sharing that passion with others and depending on their advice.
See also the other posts in the Starting Findory series.
Findory was started with a very modest amount of capital, probably too small. The on the cheap strategy meant Findory could not pay salaries or benefits. That made hiring and building a team difficult.
I did not want to bring people on part-time who were not dedicated to success of company, but I could not offer what people need -- at least a modest salary -- to come on full time.
In retrospect, I should have increased the initial capital invested, paid small salaries, and brought more people on the team. I was too concerned about the burn rate and not concerned enough about getting the right people on board quickly.
I also should have brought on advisors and formed an advisory board. The assistance and connections would have been valuable. Worries about loss of independence and dilution of ownership should have taken a back seat to getting the advice I needed.
Finally, I should have brought an angel on the team. As I learned with our lawyers, the advice and network I would have gained from a dedicated angel would have been as valuable as the funding. A modest amount of additional funding also would have been sufficient to pay 1/3 salaries to a couple employees, easing the build out of the critical early team.
It is ironic. I started Findory because I was passionate about an idea and loved the speed of execution I gained from my independence. In my excitement, I forgot the importance of sharing that passion with others and depending on their advice.
See also the other posts in the Starting Findory series.
Wednesday, September 06, 2006
Me and my jurassic Java
Last time I did any Java programming was way back in 1996. I did most of my work on Java applets and used the ancient JDK 1.0.
I did some pretty fun applets back then. I did a dialogue-based travel search called the Automated Travel Assistant that used live data screen-scraped in real-time from ITN.net (it really worked, screenshots in the UM '97 paper). I did an applet called WebView that would multi-thread crawl and display web link graphs in real-time around a URL or search terms (the look-and-feel was similar to what you can now see at TouchGraph). And, much more of a toy project, I did a little LGrammar drawing program.
In those very early days of Java, these chunks of code were some of the biggest applets around. That this is true says more about the state of Java back then than anything else.
Having been away for a decade, I recently decided to go back and look at Java again. I was surprised by how many things for which Java was promoted back in 1996 have now been dropped.
The biggest is applets. Applets are no longer emphasized as part of Java, having been supplanted by Flash and, more lately, AJAX. Way back in 1996, Java was heavily hyped for two reasons: the promise of making the web dynamic and of being platform-independent. Only the second seems to live on.
There are many more changes. The AWT was entirely rewritten back in JDK 1.1 (which, at the time, broke all my applets). There were many new libraries and interfaces added, all kinds of beany, swingy, enterprisy things.
In the most recent versions, the language even went back on some of the simplifications that were much touted by the authors of the original JDK 1.0. To name a few, there used to be no templates (which can be ugly), no enums (which, they claimed, are unnecessary syntactic sugar), and no non-blocking I/O (which, they argued, should be handled by blocking threads instead). All of those are now offered as part of JDK 4.0 and 5.0.
It is interesting to see how far Java has migrated since its early days.
I did some pretty fun applets back then. I did a dialogue-based travel search called the Automated Travel Assistant that used live data screen-scraped in real-time from ITN.net (it really worked, screenshots in the UM '97 paper). I did an applet called WebView that would multi-thread crawl and display web link graphs in real-time around a URL or search terms (the look-and-feel was similar to what you can now see at TouchGraph). And, much more of a toy project, I did a little LGrammar drawing program.
In those very early days of Java, these chunks of code were some of the biggest applets around. That this is true says more about the state of Java back then than anything else.
Having been away for a decade, I recently decided to go back and look at Java again. I was surprised by how many things for which Java was promoted back in 1996 have now been dropped.
The biggest is applets. Applets are no longer emphasized as part of Java, having been supplanted by Flash and, more lately, AJAX. Way back in 1996, Java was heavily hyped for two reasons: the promise of making the web dynamic and of being platform-independent. Only the second seems to live on.
There are many more changes. The AWT was entirely rewritten back in JDK 1.1 (which, at the time, broke all my applets). There were many new libraries and interfaces added, all kinds of beany, swingy, enterprisy things.
In the most recent versions, the language even went back on some of the simplifications that were much touted by the authors of the original JDK 1.0. To name a few, there used to be no templates (which can be ugly), no enums (which, they claimed, are unnecessary syntactic sugar), and no non-blocking I/O (which, they argued, should be handled by blocking threads instead). All of those are now offered as part of JDK 4.0 and 5.0.
It is interesting to see how far Java has migrated since its early days.
Rojo acquired and feed reader startups
Liz Gannes and Niall Kennedy report that Rojo Networks, a social feed reader, has been acquired by Six Apart, a blogging startup.
Liz points out that "there are getting to be fewer and fewer RSS reader companies."
With the entry of the giants -- Google's Google Reader, Yahoo's My Yahoo, Microsoft's Live.com, Mozilla's Firefox, and Ask's Bloglines -- this is not surprising. There is no room for little guys when the big players come in, not unless the product is unusual and well differentiated.
I have long expected the same thing happen to vanilla blog search, but I have been surprised by how well Technorati has done against competition from Google Blog Search and Ask's blog search. Things may heat up more when Microsoft and Yahoo fully launch their blog search products.
Liz points out that "there are getting to be fewer and fewer RSS reader companies."
With the entry of the giants -- Google's Google Reader, Yahoo's My Yahoo, Microsoft's Live.com, Mozilla's Firefox, and Ask's Bloglines -- this is not surprising. There is no room for little guys when the big players come in, not unless the product is unusual and well differentiated.
I have long expected the same thing happen to vanilla blog search, but I have been surprised by how well Technorati has done against competition from Google Blog Search and Ask's blog search. Things may heat up more when Microsoft and Yahoo fully launch their blog search products.
Monday, September 04, 2006
Collective delusion and Amazon.cult
I love this quote from Robert Sutton, an organizational psychologist at the Stanford School of Engineering, about "the obsessive work habits of some Silicon Valley start-ups":
One of the Amazon engineers even did a parody T-shirt for the 1998 Amazon summer picnic. The original shirt looked like this front and back:


It says, "Amazon.com: Play long, hard, and smart. At Amazon.com, you can't do two out of three."
Here is the parody:


It says, "Amazon.cult: Work long, hard, and smart. And please pass the Kool-Aid."
A bunch of us were wearing the parody version during the 1998 picnic. Fortunately, Jeff Bezos thought they were hilarious.
[Robert Sutton quote found via Findory -> SJ Mercury News]
Update: Don't miss the new details from Joshua, the creative mind behind the 1998 parody T-shirts, in the comments to this post.
They are temporary cults.Sounds like the early days at Amazon.com. We used to jokingly refer to the company as "Amazon.cult".
Any time you isolate people, bind them together and work them like dogs, it's very powerful.
You can get an enormous amount done when you create a place of such total focus and collective delusion.
One of the Amazon engineers even did a parody T-shirt for the 1998 Amazon summer picnic. The original shirt looked like this front and back:


It says, "Amazon.com: Play long, hard, and smart. At Amazon.com, you can't do two out of three."
Here is the parody:


It says, "Amazon.cult: Work long, hard, and smart. And please pass the Kool-Aid."
A bunch of us were wearing the parody version during the 1998 picnic. Fortunately, Jeff Bezos thought they were hilarious.
[Robert Sutton quote found via Findory -> SJ Mercury News]
Update: Don't miss the new details from Joshua, the creative mind behind the 1998 parody T-shirts, in the comments to this post.
Friday, September 01, 2006
Google Analytics and Bigtable
Another tidbit I found curious in the Google Bigtable paper was the massive size of the Google Analytics data set stored in Bigtable.
The paper says that 250 terabytes of Google Analytics data are stored in Bigtable. That's more than all the images for Google Earth (71T). It is the second largest data set in Bigtable, behind only the 850T of the Google crawl.
Why is it so big? The way I had assumed Google Analytics worked is that it maintained only the summary data for each website. That would be a very small amount of data, nowhere near 250T.
Instead, it appears Google Analytics keeps all the information about user behavior on all sites using Google Analytics permanently, online, and available for various analyses. That would explain 250T of data.
What data does Google Analytics collect? From the Google Analytics help page:
Google Analytics data would tell Google what people are doing on other websites, including how often they go to the site, where they came from, and what they do when they get there. It could be quite useful as part of determining the relevance of sites and how people transition between sites.
See also my previous posts, "Google Personalized Search and Bigtable" and "Google Bigtable paper".
The paper says that 250 terabytes of Google Analytics data are stored in Bigtable. That's more than all the images for Google Earth (71T). It is the second largest data set in Bigtable, behind only the 850T of the Google crawl.
Why is it so big? The way I had assumed Google Analytics worked is that it maintained only the summary data for each website. That would be a very small amount of data, nowhere near 250T.
Instead, it appears Google Analytics keeps all the information about user behavior on all sites using Google Analytics permanently, online, and available for various analyses. That would explain 250T of data.
What data does Google Analytics collect? From the Google Analytics help page:
Google Analytics uses a first-party cookie and JavaScript code to collect information about visitors and to track your advertising campaign data.The data would be quite useful. The Google crawl only gives information about the web pages out there. Google search logs only give information about what people search for and what search results they click on.
Google Analytics anonymously tracks how visitors interact with a website, including where they came from, what they did on a site, and whether they completed any of the site's conversion goals.
Analytics also keeps track of your e-commerce data, and combines this with campaign and conversion information to provide insight into the performance of your advertising campaigns.
Google Analytics data would tell Google what people are doing on other websites, including how often they go to the site, where they came from, and what they do when they get there. It could be quite useful as part of determining the relevance of sites and how people transition between sites.
See also my previous posts, "Google Personalized Search and Bigtable" and "Google Bigtable paper".
AOL Research has been shut down
The AOL Research group has been shut down.
In the wake of the privacy firestorm over their attempt to provide log data to researchers, it appears AOL has decided to eliminate their research group and stop working with the academic research community.
I am saddened by this news. It is very disappointing.
In the wake of the privacy firestorm over their attempt to provide log data to researchers, it appears AOL has decided to eliminate their research group and stop working with the academic research community.
I am saddened by this news. It is very disappointing.
Google Image Labeler and ESP Game
Google has launched a clone of the ESP Game with the rather dull name Google Image Labeler.
Google Image Labeler is a simple game where two anonymous, random people try to agree on labels for images. The idea here is to get people to do useful work, such as providing accurate labels for images, by trying to make it into a fun game.
See also my earlier post, "Human computation and playing games", where I talk about ESP Game and Luis von Ahn's other work in more detail.
See also Luis von Ahn's talk at Google on Google Video, "Human Computation". It is a light, fun, and very interesting talk that includes demos of these types of games and the value of the data derived from the games.
[Found via Philipp Lenssen]
Update: Danny Sullivan reports that Google licensed the ESP Game from Luis von Ahn.
Update: A Google engEDU talk on Google Video, "Using Statistics to Search and Annotate Pictures", by UCSD Professor Nuno Vasconcelos gives some nice examples of how this kind of image labeling data can be useful for image search.
Update: A couple other talks are worth considering here as well. First, a talk "Detecting and Recognizing Objects In Natural Images" might be another in a long line of applying probabilistic models to finding objects in images, but I particularly enjoyed the demo at 15:00 of their text recognition in that talk. Second, I thought "Automated Reconstruction of 3D Models" had some impressive ideas about how to quickly get detailed 3D city models into mapping software like Google Maps and Google Earth.
Google Image Labeler is a simple game where two anonymous, random people try to agree on labels for images. The idea here is to get people to do useful work, such as providing accurate labels for images, by trying to make it into a fun game.
See also my earlier post, "Human computation and playing games", where I talk about ESP Game and Luis von Ahn's other work in more detail.
See also Luis von Ahn's talk at Google on Google Video, "Human Computation". It is a light, fun, and very interesting talk that includes demos of these types of games and the value of the data derived from the games.
[Found via Philipp Lenssen]
Update: Danny Sullivan reports that Google licensed the ESP Game from Luis von Ahn.
Update: A Google engEDU talk on Google Video, "Using Statistics to Search and Annotate Pictures", by UCSD Professor Nuno Vasconcelos gives some nice examples of how this kind of image labeling data can be useful for image search.
Update: A couple other talks are worth considering here as well. First, a talk "Detecting and Recognizing Objects In Natural Images" might be another in a long line of applying probabilistic models to finding objects in images, but I particularly enjoyed the demo at 15:00 of their text recognition in that talk. Second, I thought "Automated Reconstruction of 3D Models" had some impressive ideas about how to quickly get detailed 3D city models into mapping software like Google Maps and Google Earth.
Subscribe to:
Posts (Atom)
